Datafacer
Pour Ocelet, un datafacer est un moyen d'établir un lien entre des données et les objets manipulés dans un modèle.
Ne cherchez pas dans le dictionnaire, nous avons mélangé les mots Data et Interface pour construire le mot Datafacer.
Chaque type de datafacer concerne un format de données particulier.
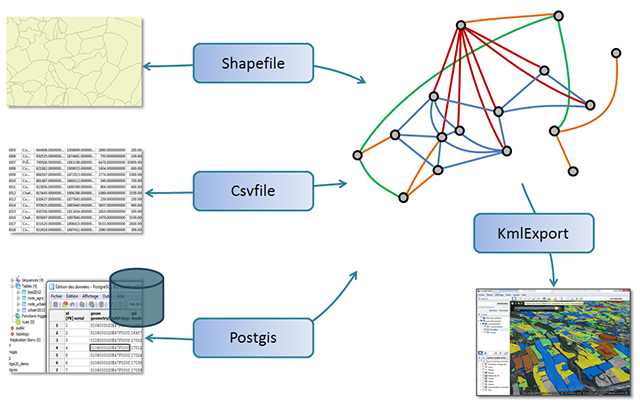
On doit définir et paramétrer chaque datafacer dont on a besoin avant de pouvoir l'utiliser dans un scénario. Tous les datafacers ont en commun une syntaxe de définition de base qui est minimale, mais leur paramétrage dépend très largement du type de datafacer, c'est à dire du format de données pour lequel il est spécialisé.
On pourra en réalité distinguer deux catégories dans les formats de données : ceux qui peuvent être assimilés à des tableaux (avec des lignes et des colonnes) et les autres qui ne sont pas structurés sous cette forme. Pour tous les formats de données assimilables à des tableaux (Shapefile, Base de données relationnelles, fichiers de tableur (csv)) on retrouvera des grandes similarités dans la définition et dans les fonctionnalités disponibles.
La première section de cette documentation apporte des indications sur la syntaxe commune à tous les datafacers, mais aussi aux éléments que l'on retrouve pour les formats assimilables à des tableaux. Les sections suivantes sont chacune dédiée à un format de donnée particulier.
Contenu
Syntaxes génériques
Définition d'un datafacer
datafacernom du datafacer{datatype de datafacer(paramètres pour la source ou la destination des données)
déclarations spécifiques à chaque type de datafacer}
Le nom du datafacer doit impérativement commencer par une lettre (majuscule de préférence) mais peut éventuellement être suivi par des chiffres, et ne pas contenir d'espace ni de caractère spéciaux.
Formats de données tabulaires
Dans la version actuelle d'Ocelet, les formats considérés comme tabulaires sont :
Ces formats de stockage de données ont en commun le fait d'avoir un enregistrement par ligne et une propriété (ou attribut) par colonne.
Nous avons voulu tirer parti de cette structure pour faciliter la création d'une série d'entités (une par enregistrement) avec une initialisation automatique de leur propriétés à partir du contenu des colonnes. Il suffit pour cela de spécifier une correspondance entre une propriété de l'entité et une colonne du tableau de données.
La syntaxe qui permet de spécifier cette correspondance est la suivante :
datafacernom du datafacer{datatype de datafacer(paramètres pour la source ou la destination des données)matchcatégorie d'entité{
propriété:"nom de colonne"
propriété:"nom de colonne"
...
propriété:"nom de colonne"}}
On notera que pour les fichiers de type csv, la première ligne doit contenir des noms de colonne de façon à pouvoir utiliser ces noms dans la clause match.
Voici un premier exemple dans le cas d'un fichier au format csv :
entity MyEntity {
property Integer id
property String nom
property Integer pop
}
datafacer CsvData {
data Csvfile("data/mydatafile.csv")
match MyEntity {
id : "gid"
nom : "pays"
pop : "population"
}
}Cet exemple permettra de produire une série d'entités MyEntity (une entité pour chaque ligne du fichier csv) initialisées avec le contenu des colonnes gid, pays et population.
Utilisation dans un scenario
Dans un scenario, on commence par créer une variable qui contiendra un exemplaire du datafacer (on peut en faire plusieurs si besoin), puis on l'utilise en appellant des fonctions prédéfinies. Ces fonctions sont pour la plupart propres à chaque type de datafacer.
Les datafacers de format de données tabulaires ont en commun la fonction :
List<MonEntite> readAll_MonEntite_() : Construit une liste d'entités de la catégorie MonEntite. Chaque entité contenue dans cette liste a été initialisée avec les valeurs d'une ligne du tableau de données en respectant la correspondance spécifiée dans la partie match{...} du datafacer.
En complément de l'exemple précédent, si le fichier mydatafile.csv contient les valeurs :
gid;pays;population
1;France;66000000
2;Espagne;47000000
3;Portugal;10000000On pourra obtenir une liste de 3 entités avec les instructions suivantes :
let cvsdataf = new CsvData
let myEntities = csvdataf.readAllMyEntity() Chaque élément de la liste myEntities sera un exemplaire de MyEntity dont les propriétés ont les valeurs d'une ligne du fichier.
Lecture de données dans une KeyMap
Avec les datafacers Csvfile, Postgis et Shapefile on dispose d'une fonction readToKeyMap(String keypropertyname) qui permet de lire les données directement dans une KeyMap.
Comme pour readAll() chaque ligne de donnée produit une instance d'entité. Cette entité est ajoutée dans une KeyMap, associée à une clé qui est la valeur de la propriété que l'on a indiqué en paramètre.
Il est donc prudent de s'assurer que la propriété que l'on choisit comme clé ne contient que des valeurs uniques sinon on risque de ne pas obtenir toutes les entités contenues dans la source de données.
Exemple
entity Parc {
property Integer id
property MultiPolygon geom
property String own
}
datafacer Dplots {
data Shapefile("data/AgPlots.shp","EPSG:32740")
match Parc {
id: "PID"
geom : "geom"
own : "OWNER"
}
scenario MyModel {
fix dplots = new Dplots
fix plotsbyid = dplots.readToKeyMap("id")
println(""+plotsbyid.get(4))
}Systeme de coordonnées d'un modèle
Il est possible de spécifier le système de coordonnées de référence pour un modèle directement, sans avoir besoin de lire un fichier de données.
setModelCRS(String epsgcode)On peut l'utiliser dans un scénario soit comme ceci :
setModelCRS("EPSG:32740")soit comme cela :
modelCRS = "EPSG:32740"Csvfile
Type de datafacer permettant la lecture et l'écriture de fichiers texte contenant un tableau de données, dont les champs sont séparés par un point-virgule (coma separated values : csv). Le point virgule ; est le caractère séparateur par défaut mais il et possible d'en spécifier un autre.
Ce type de fichier peut être produit à partir d'une simple editeur de texte, ou exporté depuis un tableur.
Voici un petit fichier au format csv qui sera utilisé dans les exemples de code de cette section :
num;pays;superficie;population
1;Mauritius;2040;1260000
2;Madagascar;587040;23813000
3;Seychelles;455;91650
4;Comores;2236;767000Il est important de noter que la première ligne contient les noms de colonnes. Il est impératif de fournir ces noms de colonnes sur la première ligne de façon à pouvoir nommer ces colonnes dans la définition du datafacer.
Définition d'un datafacer de type Csvfile
La fonction de construction pour définir un datafacer de ce type eput s'utiliser de deux manières :
Csvfile(String nom_de_fichier)
Csvfile(String nom_de_fichier, String separateur)
Dans les deux cas le nom de fichier doit contenir le chemin permettant d'accéder au fichier.
Si un caractère séparateur est spécifié, il sera utilisé à la place du point-virgule pour distinguer les valeurs contenues sur une ligne.
Rappel : La première ligne des fichiers au format csv doit contenir le nom des colonnes.
Exemple de définition d'un datafacer de type Csvfile
datafacer CsvData {
data Csvfile("data/mydatafile.csv")
match Pays {
id : "num"
nom : "pays"
pop : "population"
}
}Cet exemple suppose que l'on ait défini par ailleurs la catégorie d'entité Pays :
entity Pays {
property Integer id
property String nom
property Double pop
}Cette définition de datafacer prépare la lecture ou l'écriture d'un fichier dont les valeurs sont séparées par le caractère par défaut ;. Si les colonnes de valeurs étaient par exemple séparées par le caractère | on devrait utiliser la deuxième forme pour indiquer ce séparateur : data Csvfile("data/mydatafile.csv","|").
On remarquera que nous ne sommes pas obligé d'établir une correspondance avec toutes les colonnes du tableau contenu dans le fichier csv. Dans notre exemple, l'entité Pays contient trois propriétés, alors que le fichier en contient quatre. La colonne contenant la superficie ne nous intéressait pas, nous ne l'avons pas utilisé dans la définition du datafacer.
Une fois que ce datafacer a été défini, il peut être utilisé dans un scenario.
Utilisation d'un datafacer Csvfile dans un scenario
La première chose à faire est d'affecter une variable avec un exemplaire (une instance) du datafacer que l'on a défini. Ce qui avec notre exemple peut s'écrire de la façon suivante :
fix csvdat = new CsvDataEnsuite on peut faire appel à des fonctions d'usage propres aux datafacers Csvfile pour lire ou écrire des données ou encore pour changer le nom de fichier.
append() : écriture dans un fichier de type csv
Pour ajouter une seule ligne au fichier on dispose de la fonction :
append(Entity entite_a_ecrire)
Le type Entity indiqué dans cette définition doit être compris comme étant en réalité la catégorie d'entité qui a été déclarée dans la clause match de la définition du datafacer.
Exemple :
csvdat.append(new Pays=>[id=8 nom="Mozambique" pop=25900000.0])Cette ligne a pour effet de créer une nouvelle entité Pays initalisée avec des données sur le Mozambique et ajouter une ligne à la fin du fichier csv avec ces propriétés.
Pour ajouter plusieurs lignes d'un coup, c'est la même fonction mais on peut lui passer une liste d'entités :
append(List<Entity> liste_des_entites_a_ajouter_au_fichier )
Ici aussi, le type Entity indiqué dans cette définition doit être compris comme étant en réalité la catégorie d'entité qui a été déclarée dans la clause match de la définition du datafacer.
readAll() : lecture d'un fichier csv
Deux formes sont disponible pour cette fonction :
readAll()
readAllNom de l'entité spécifiée dans match()
Ces deux fonctions sont équivalentes. Elles ont pour effet de construire une liste d'entités de la catégorie déclarée dans la clause match, c'est à dire Pays dans l'exemple qui précède. Chaque entité contenue dans cette liste a été initialisée avec les valeurs d'une ligne du tableau de données en respectant la correspondance spécifiée dans la partie match{...} du datafacer.
Par exemple pour lire les données et produire une liste d'entités on écrira :
fix liste_pays = csvdat.readAll // liste_pays contient une liste d'entités initialisées
// Pour vérifier, on peut afficher le contenu que l'on a lu :
for (pays:liste_pays) println(pays.nom+" population:"+pays.pop)Dans ce même exemple on aussi aurait pu écrire fix liste_pays = csvdat.readAllPays avec un résultat équivalent.
remove() : supprimer le fichier
Syntaxe :
remove()
Cette fonction a pour effet de supprimer le fichier csv pointé par ce datafacer.
Si le fichier en question n'existe pas, la fonction de fait rien et ne produit pas de message d'erreur. Cela permet de faire appel à remove() avant un append() pour s'assurer que l'on ne va pas ajouter des enregistrements à un fichier déjà présent.
csvdat.setFilename("output/Resultats.csv")
csvdat.remove
csvdat.append(listeResultats)Dans cet exemple on aura créé un nouveau fichier Resultats.csv en s'assurant qu'il ne contiendra rien d'autre que les entités de listeResultats.
setFileName() : changer le nom du fichier
Syntaxe :
setFileName(String nom_de_fichier)
Si nous avons un deuxième fichier csv, structuré comme le premier (c'est à dire avec les mêmes types et noms de colonnes), il est possible de l'utiliser à partir du même datafacer mais en changeant juste le nom.
csvdat.setFileName("data/myOtherdatafile.csv")
fix liste_pays2 = csvdat.readAllA l'issue de ces deux lignes, liste_pays2 contient une nouvelle liste d'entités initialisée avec le contenu du nouveau fichier
Les fonctions dont le nom commence par set peuvent être utilisées sans le set, comme si on mettait à jour une variable.
Ici on peut donc aussi écrire : csvdat.fileName = "data/myOtherdatafile.csv" le résultat sera le même.
setSeparator() : changer le séparateur
Il est possible de changer le caractère séparateur déclaré pour un datafacer de type Csvfile. Cela peut être utile par exemple pour lire des données dans un fichier avec un séparateur puis écrire des données (à partir d'un même type d'entités) dans un autre fichier avec un séparateur différerent, sans avoir à définir un deuxième datafacer.
On dispose pour cela de la fonction :
setSeparator(String nouveau_separateur)
Exemple :
csvdat.setSeparator(",")Les fonctions dont le nom commence par set peuvent être utilisées sans le set, comme si on mettait à jour une variable.
Ici on peut donc aussi écrire : csvdat.separator = "," le résultat sera le même.
Shapefile
Type de datafacer permettant la lecture et l'écriture de fichiers au format Shapefile d'ESRI. Ce format est aussi parfois appellé fichier de forme. Davantage d'information à propos de ce format de fichier est disponible sur Wikipedia ou encore dans la documentation d'ArcGIS.
Pour les besoins de cette documentation, rappellons que les données enregistrées au format shapefile sont en réalité contenues dans trois fichiers au minimum (portant les extentions shp, shx et dbf) et qu'il est impératif de conserver ensemble ces trois fichiers sans quoi la cohérence de l'ensemble n'est plus assurée. En pratique on ne fait référence qu'au fichier portant l'extension shp et la présence des deux autres est implicite.
Définition d'un datafacer de type Shapefile
On définit un datafacer Shapefile à l'aide de la fonction :
Shapefile(String nom_de_fichier, String codeEPSG)
- Le premier argument est simplement le nom (et le chemin) du fichier portant l'extension
.shp. - Le second argument est l'indication du système de coordonnées utilisé pour les données géographiques contenues dans ce fichier. Pour ne pas avoir a détailler les paramètres caractérisant l'ellipsoïde de référence et la projection, nous indiquons seulement le code EPSG correspondant. Par exemple si les données concernent l'île de la Réunion, et que l'on a fait appel au système RGR92 (Référentiel Géographique de la Réunion), on indiquera le code du système correspondant sous la forme : "EPSG:2975".
Exemple de définition d'un datafacer de type Shapefile
Prenons le cas d'un parcellaire (agricole, cadastral ou autre). Nous devons d'abord avoir préparé une entité qui va porter les propriétés de ces parcelles:
entity Parcelle {
property Integer id
property Integer ocsol
property Double surface
property String proprietaire
property MultiPolygon geom
}Et la définition du datafacer va faire référence à cette entité (à travers la clause match) :
datafacer Parcellaire {
data Shapefile("data/AgPlots.shp","EPSG:2975")
match Parcelle {
id : "pid"
ocsol : "lct"
geom : "the_geom"
}
}Cette définition de datafacer prépare la lecture ou l'écriture d'un fichier au format Shapefile nommé AgPlots. Seul le fichier .shp est indiqué mais en cas de lecture, les deux fichiers AgPlots.shx et AgPlots.dbf doivent impérativement se trouver dans le même répertoire. En cas d'écriture, si ces fichiers n'existent pas encore, ils seront créés tous les trois au moment de l'enregistrement.
Dans la clause match on définit la correspondance entre des propriétés de l'entité Parcelle : id, ocsol et geom et des noms d'attributs (ou nom de colonne) du shapefile : "pid", "lct" et "the_geom".
L'attribut "the_geom" désigne la forme géométrique contenue dans un enregistrement. Il peut s'agir de point, ligne, polygone, ou (comme c'est plus souvent le cas) de leur forme multiple : multipoint, multiligne ou multipolygone.
Pour connaitre la nature des géométries contenues dans un shapefile, il peut être utile d'utiliser la fonction about() de ce datafacer.
Une fois que ce datafacer a été défini, il peut être utilisé dans un scenario.
Utilisation d'un datafacer Shapefile dans un scenario
La première chose à faire est d'affecter une variable avec un nouvel exemplaire (une instance) du datafacer que l'on a défini. Ce qui avec notre exemple peut s'écrire de la façon suivante :
fix dataparc= new ParcellaireEnsuite on peut faire appel à des fonctions d'usage propres aux datafacers Shapefile pour lire ou écrire des données ou encore pour changer le nom de fichier, etc.
about() : que contient ce shapefile ?
Quand on ne sait pas exactement de quel type sont les attributs d'un shapefile, ou comment sont orthographiés les noms des attributs (pour pouvoir y faire référence dans une clause match par exemple), la fonction about() peut fournir ces informations.
Cette fonction donne un aperçu de ce que Ocelet peut lire comme information dans un shapefile. Sa syntaxe est la suivante :
String about()
Autrement dit en appellant about sur un datafacer shapefile on obtient un texte qu'il est possible de faire afficher.
Exemple d'utilisation de cette fonction, dans lequel on montre aussi qu'il n'est pas toujours nécessaire de définir une clause match dans la définition d'un datafacer Shapefile :
scenario Shp_Aboutdemo {
fix dataparc = new Parcellaire
println(dataparc.about())
}
datafacer Parcellaire {
data Shapefile("data/AgPlots.shp","EPSG:2975")
}Dans cet exemple nous avons mis les parenthèses : dataparc.about() mais comme il n'y a rien à passer en argument de cette fonction, ces parenthèses sont optionnelles, on peut aussi écrire dataparc.about et obtenir le même résultat.
L'exécution du scénario de cet exemple aura pour effet d'afficher dans la console :
Shapefile : AgPlots
Contains 678 records.
Coordinate reference system : WGS_1984_UTM_Zone_40S
Bounds : 363007.54725825915 7645776.8813113645 , 368557.25827995676 7652774.407732953
Description of the 7 attributes :
[1] : the_geom : MultiPolygon
[2] : ALT_M : Double
[3] : SURF : Double
[4] : PID : Integer
[5] : OWNER : String
[6] : LCT : Integer
[7] : LASTFALLOW : Integerappend() : écriture dans un shapefile
Pour ajouter une seule ligne au fichier on dispose de la fonction :
append(Entity entite_a_ecrire)
Le type Entity indiqué dans cette définition doit être compris comme étant en réalité la catégorie d'entité qui a été déclarée dans la clause match de la définition du datafacer.
Exemple :
let p5 = liste_parc.get(5)
p5.proprietaire = "David"
dataparc.append(p5)Cette ligne a pour effet d'enregistrer dans le shapefile l'entité parcelle passée à append().
Pour ajouter plusieurs lignes d'un coup, c'est la même fonction mais on peut lui passer une liste d'entités :
append(List<Entity> liste_des_entites_a_ajouter_au_fichier )
Ici aussi, le type Entity indiqué dans cette définition doit être compris comme étant en réalité la catégorie d'entité qui a été déclarée dans la clause match de la définition du datafacer.
Dans le cas où le shapefile n'existe pas encore, il sera créé et les enregistrements seront ajoutés. Dans le cas où le shapefile existe déjà, les enregistrements seront ajoutés à la suite de ceux qui sont présents.
Attention lorsque l'on ajoute des enregistrements à un shapefile existant, il faut que les noms de colonnes, leur nombre et leur type soient identiques à ceux du shapefile existant.
readAll() : lecture d'un fichier shapefile
Deux formes sont disponible pour cette fonction :
readAll()
readAllNom de l'entité spécifiée dans match()
Ces deux fonctions sont équivalentes. Elles ont pour effet de construire une liste d'entités de la catégorie déclarée dans la clause match, c'est à dire Parcelle dans l'exemple qui précède. Chaque entité contenue dans cette liste sera initialisée avec les valeurs d'un enregistrement du shapefile en respectant la correspondance spécifiée dans la partie match{...} du datafacer.
Par exemple pour lire les données et obtenir une liste d'entités Parcelle on écrira :
fix liste_parc = dataparc.readAll // liste_parc contient une liste d'entités initialisées
// Pour vérifier et savoir combien d'enregistrements ont été lus
// on peut par exemple afficher la taille de la liste :
println("Nous avons obtenu "+liste_parc.size+" entités Parcelle.")Dans ce même exemple on aussi aurait pu écrire fix liste_parc = dataparc.readAllParcelle avec un résultat équivalent.
remove() : supprimer le shapefile
Syntaxe :
remove()
Cette fonction a pour effet de supprimer les fichiers qui constituent le shapefile (.shp, .shx, .dbf).
Si le shapefile en question n'existe pas, la fonction ne fait rien et ne produit pas de message d'erreur. Cela permet de faire appel à remove() avant un append() pour s'assurer que l'on ne va pas ajouter des enregistrements à un fichier shapefile déjà présent.
dataparc.setFilename("output/Resultats.shp")
dataparc.remove
dataparc.append(listeParcelles)Dans cet exemple on aura créé un nouveau shapefile Resultats.shp en s'assurant qu'il ne contiendra rien d'autre que les entités de listeParcelles.
setCrs() : changer le système de coordonnées du fichier
Syntaxe :
setCrs(String codeEPSG)
Si l'on souhaite enregistrer une liste d'entités au format Shapefile mais en changeant le système de coordonnées, il faut utiliser cette fonction pour indiquer le système de coordonnées cible sous la forme "EPSG:code" avant de faire appel à une fonction append(liste_entites).
setFileName() : changer le nom du fichier
Syntaxe :
setFileName(String nom_de_fichier)
Si nous avons un deuxième fichier shapefile, structuré comme le premier (c'est à dire avec les mêmes types et noms de colonnes), il est possible de l'utiliser à partir du même datafacer mais en changeant juste le nom.
dataparc.setFileName("data/AgPlots_2.shp")
fix liste_parc2 = dataparc.readAllA l'issue de ces deux lignes, liste_parc2 contient une nouvelle liste d'entités initialisée avec le contenu du nouveau fichier.
Les fonctions dont le nom commence par set peuvent être utilisées sans le set, comme si on mettait à jour une variable.
Ici on peut donc aussi écrire : dataparc.fileName = "data/AgPlot_2.shp" le résultat sera le même.
Postgis
Type de datafacer permettant la lecture et l'écriture d'enregistrements dans une base de données Postgresql dotée de l'extension spatiale PostGIS.
Définition d'un datafacer de type Postgis
On définit un datafacer Postgis à l'aide de la fonction :
Postgis(String serveur, String port, String base, String schema, String table, String utilisateur, String mot_de_passe, String codeEPSG)
Détail des arguments à fournir :
- serveur : adresse du serveur de base de données. Si le serveur est installé dans le même ordinateur qu'Ocelet, cette adresse sera "localhost"
- port : numéro de port pour accéder au serveur. Par défaut cette valeur est "5432".
- base : nom de votre base de données
- schema : nom du schema ou se trouve la table
- table : nom de la table à laquelle on veut accéder
- utlisateur : identifiant d'utilisateur pour cette base
- mot_de_passe : mot de passe d'utilisateur pour cette base
- codeEPSG : indication du système de coordonnées utilisé pour les données géographiques contenues dans cette table. Pour ne pas avoir a détailler les paramètres caractérisant l'ellipsoïde de référence et la projection, nous indiquons seulement le code EPSG correspondant. Par exemple si les données concernent l'île de la Réunion, et que l'on a fait appel au système RGR92 (Référentiel Géographique de la Réunion), on indiquera le code du système correspondant sous la forme : "EPSG:2975".
Exemple de définition d'un datafacer de type Postgis
Prenons le cas d'un parcellaire (agricole, cadastral ou autre). Nous devons d'abord avoir préparé une entité qui va porter les propriétés de ces parcelles:
entity Parcelle {
property Integer id
property Integer ocsol
property Double surface
property String proprietaire
property MultiPolygon geom
}Et la définition du datafacer va faire référence à cette entité (à travers la clause match) :
datafacer BaseParcellaire {
data Postgis("localhost","5432","MyOceletBase","public","AgPlots","utilisateur","motdepasse","EPSG:2975")
match Parcelle {
id : "pid"
proprietaire : "owner"
ocsol : "lct"
geom : "the_geom"
}
}Cette définition de datafacer prépare la lecture ou l'écriture d'une table nommée public.AgPlots (public étant le nom de schema) appartenant à la base de données MyOceletBase.
Dans la clause match on définit la correspondance entre des propriétés de l'entité Parcelle : id, ocsol, geom ... et des noms de colonne de la table AgPlots : "pid", "lct" et "the_geom" ...
L'attribut "the_geom" désigne la forme géométrique contenue dans un enregistrement. Il peut s'agir de point, ligne, polygone, ou (comme c'est plus souvent le cas) de leur forme multiple : multipoint, multiligne ou multipolygone.
Pour connaitre la nature des géométries contenues dans une table de base de données, il peut être utile d'utiliser la fonction about() de ce datafacer.
Une fois que ce datafacer a été défini, il peut être utilisé dans un scenario.
Utilisation d'un datafacer Postgis dans un scenario
La première chose à faire est d'affecter une variable avec un nouvel exemplaire (une instance) du datafacer que l'on a défini. Ce qui avec notre exemple peut s'écrire de la façon suivante :
fix dataparc= new BaseParcellaireEnsuite on peut faire appel à des fonctions d'usage propres aux datafacers Postgis pour lire ou écrire des données.
about() : que contient cette table ?
Quand on ne sait pas exactement de quel type sont les attributs de la table (du point de vue d'Ocelet), ou comment sont orthographiés les noms des attributs (pour pouvoir y faire référence dans une clause match par exemple), la fonction about() peut fournir ces informations.
Cette fonction donne un aperçu de ce que Ocelet peut lire comme information à propos de la structure de la table concernée. Sa syntaxe est la suivante :
String about()
Autrement dit en appellant about sur un datafacer de type Postgis on obtient un texte qu'il est possible de faire afficher.
Exemple d'utilisation de cette fonction :
scenario Postgis_Aboutdemo {
fix dataparc = new Parcellaire
println(dataparc.about())
}
datafacer Parcellaire {
data Postgis("localhost","5432","MyOceletBase","public","AgPlots","postgres","postgres","EPSG:2975")
}Dans cet exemple nous avons mis les parenthèses : dataparc.about() mais comme il n'y a rien à passer en argument de cette fonction, ces parenthèses sont optionnelles, on peut aussi écrire dataparc.about et obtenir le même résultat.
L'exécution du scénario de cet exemple aura pour effet d'afficher dans la console :
Table : AgPlots
Contains 678 records.
Coordinate reference system : EPSG:RGR92 / UTM zone 40S
Bounds : 363007.53125 7645776.5 , 368557.28125 7652774.5
Description of the 7 attributes :
[1] : geom : MultiPolygon
[2] : alt_m : Double
[3] : surf : Double
[4] : pid : Integer
[5] : owner : String
[6] : lct : Integer
[7] : lastfallow : Integerappend() : écriture d'enregistrements dans une table de base Postgis
Pour ajouter un seul enregistrement dans la table, on dispose de la fonction :
append(Entity entite_a_ecrire)
Le type Entity indiqué dans cette définition doit être compris comme étant en réalité la catégorie d'entité qui a été déclarée dans la clause match de la définition du datafacer.
Exemple :
let p5 = liste_parc.get(5)
p5.proprietaire = "David"
dataparc.append(p5)Cette ligne a pour effet d'enregistrer dans la table l'entité parcelle passée à append().
Pour ajouter plusieurs enregistrements d'un coup, c'est la même fonction mais on peut lui passer une liste d'entités :
append(List<Entity> liste_des_entites_a_ajouter)
Ici aussi, le type Entity indiqué dans cette définition doit être compris comme étant en réalité la catégorie d'entité qui a été déclarée dans la clause match de la définition du datafacer.
Dans le cas ou la table n'existe pas encore dans la base de données, celle-ci sera créée (à condition d'avoir les droits de création et d'écriture) et les enregistrements seront ajoutés. Dans le cas où la table existe déjà, les enregistrements seront ajoutés à la suite de ceux qui sont présents.
Attention lorsque l'on ajoute des enregistrements à une table existante, il faut que les noms de colonnes, leur nombre et leur type soient identiques à ceux déjà présents dans cette table.
readAll() : lecture d'enregistrements d'une table Postgis
Deux formes sont disponibles pour cette fonction :
readAll()
readAllNom de l'entité spécifiée dans match()
Ces deux fonctions sont équivalentes. Elles ont pour effet de construire une liste d'entités de la catégorie déclarée dans la clause match, c'est à dire Parcelle dans l'exemple qui précède. Chaque entité contenue dans cette liste sera initialisée avec les valeurs d'un enregistrement de la table indiquée dans la définition du datafacer, en respectant la correspondance spécifiée avec la clause match{...}.
Par exemple pour lire les données et obtenir une liste d'entités Parcelle on écrira :
fix liste_parc = dataparc.readAll // liste_parc contient une liste d'entités initialisées
// Pour vérifier et savoir combien d'enregistrements ont été lus
// on peut par exemple afficher la taille de la liste :
println("Nous avons obtenu "+liste_parc.size+" entités Parcelle.")Dans ce même exemple on aussi aurait pu écrire fix liste_parc = dataparc.readAllParcelle avec un résultat équivalent.
remove() : supprimer la table
Syntaxe :
remove()
Cette fonction a pour effet de supprimer de la base de données la table pointée par ce datafacer.
KmlExport
Type de datafacer qui permet de produire des fichiers au format KML (Keyhole Markup Langage), que l'on peut ouvrir et afficher avec de nombreux logiciels SIG et globe virtuels. Ce format est notamment utilisé par le globe virtuel Google Earth qui reconnait les balises temporelles de kml et dispose d'une capacité à afficher des cartes dynamiques.
Définition d'un datafacer de type KmlExport
On définit un datafacer KmlExport à l'aide de la fonction :
KmlExport(String nom_de_fichier)
Le seul argument à fournir est le nom (et le chemin) du fichier kml que l'on souhaite produire.
Exemple de définition d'un datafacer de type KmlExport
datafacer KmlExp {
data KmlExport("output/parcellaire.kml")
}Cette définition prépare l'écriture d'un fichier kml dans le répertoire output du projet.
Utilisation d'un datafacer KmlExport dans un scenario
Dans un scenario ce type de datafacer s'utilise en quatre étapes :
- Affectation d'une variable avec un nouvel exemplaire (instance) du datafacer.
- Ajout de définitions de styles de rendu (couleurs, epaisseurs de traits, etc.)
- Ajout de contenu.
- Enregistrement effectif du fichier soit au format kml soit au format kmz.
L'affectation d'une variable s'effectue comme dans l'exemple suivant :
fix kmlexp = new KmlExpL'ajout de définitions de styles s'effectue au moyen des fonctions defIconStyle(), defStyle() et defStyleRange() qui sont documentées en détails un peu plus bas dans cette page.
L'ajout de contenu s'effectue au moyen des fonctions addFolder(), addGeometry(), addLabel() et add3DModel() qui sont documentées en détails un peu plus bas dans cette page.
Enfin l'enregistrement effectif du fichier s'effectue au moyen de l'une des deux fonctions saveAsKml() ou saveAsKmz() selon le format que l'on choisit. Le format kml est un format texte issu de XML, il peut éventuellement être consulté (et modifié à la main) avec un éditeur de texte. Le format kmz est simplement une version compréssée du kml : le contenu est identique, la taille du fichier est réduite, mais on ne peut pas directement consulter ni modifier le fichier.
Pour résumer voici un exemple minimal de production d'un fichier kml comprenant les quatre étapes :
scenario Kml_exemple {
fix dataparc = new Parcellaire
fix liste_parc = dataparc.readAllParcelle
// etape 1 : affectation d'une variable avec un nouveau datafacer kml
fix kmlexp = new KmlExp
// etape 2 : ajout d'une définition de style
kmlexp.defStyle("greenstyle",1,Color|rgb(0,128,64),Color|rgb(128,255,128))
// etape 3 : ajout de contenu
for (parc:liste_parc) {
kmlexp.addGeometry("","","",parc.geom,"greenstyle",0)
}
// etape 4 : enregistrement effectif du fichier (en format kml)
kmlexp.saveAsKml
}
datafacer KmlExp {
data KmlExport("output/parcellaire.kml")
}
entity Parcelle {
property Integer id
property Integer ocsol
property Double surface
property String own
property MultiPolygon geom
}
datafacer Parcellaire {
data Shapefile("data/AgPlots.shp","EPSG:2975")
match Parcelle {
id : "PID"
ocsol : "LCT"
own : "owner"
geom : "the_geom"
}
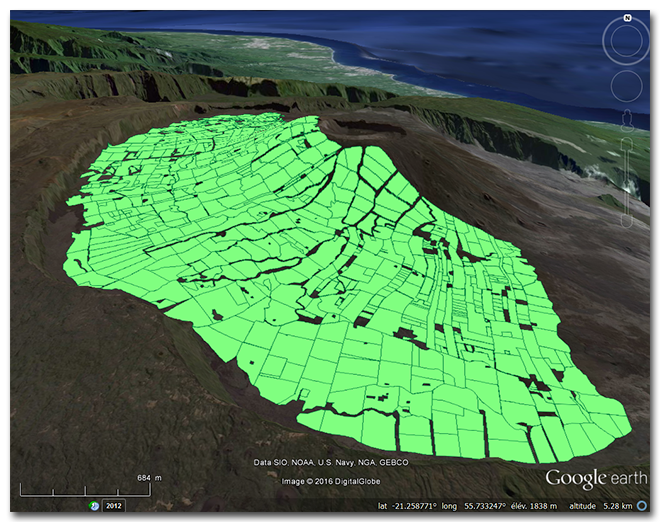
}Le fichier output/parcellaire.kml produit par cet exemple peut être ensuite affiché dans Google Earth et ressemble à ceci :
addFolder() : regroupement de plusieurs calques d'information géographique dans un dossier
Le format kml permet la création de plusieurs calques qui se surperposent et que l'on peut individuellement allumer ou éteindre lorsqu'ils sont représentés sur une carte. Pour allumer ou éteindre des ensembles de calques d'un coup, il est possible de les regrouper dans des dossiers. Dans Google Earth, ces dossiers sont visibles dans la légende, avec leur contenu. La fonction addFolder() sert à ajouter un nouveau dossier (vide) dans un datafacer kmlExport :
addFolder(String nom_de_dossier, Date date_debut, Date date_fin)
addFolder(String nom_de_dossier, String date_debut, String date_fin)
Détail des arguments :
- nom_de_dossier : identifiant du dossier à créer.
- date_debut : date à laquelle le contenu de ce dossier apparaitra sur la carte
- date_fin : date à laquelle le contenu de ce dossier disparaitra de la carte
La fonction addFolder() n'est pas la seule méthode pour ajouter un dossier au datafacer, on peut aussi le faire directement avec certaines versions de la fonction addGeometry().
addGeometry() : ajouter des points, des lignes ou des polygones.
La fonction addGeometry() permet d'ajouter les différentes formes d'objets de géométrie (ponctuels, linéaires ou surfaciques) au contenu d'un datafacer.
Cette fonction est proposée sous plusieurs formes. Les deux premières sont équivalentes, il n'y a que la façon de fournir les dates de début et de fin d'affichage qui changent. Les deux suivantes ajoutent la possibilité d'indiquer un dossier dans lequel ces objets seront regroupés :
addGeometry(String identifiant, String date_debut, String date_fin, Geometry geom, String style, Double hauteur)
addGeometry(String identifiant, Date date_debut, Date date_fin, Geometry geom, String style, Double hauteur)
addGeometry(String dossier, String identifiant, String date_debut, String date_fin, Geometry geom, String style, Double hauteur)
addGeometry(String dossier, String identifiant, Date date_debut, Date date_fin, Geometry geom, String style, Double hauteur)
Détail des arguments :
- dossier : identifiant du dossier dans lequel les objets de géométrie seront ajoutés. Si ce dossier n'existe pas encore dans le datafacer, il sera créé automatiquement.
- identifiant : identifiant de l'objet qui apparaitra dans la légende.
- date_debut : date à laquelle cet objet va apparaitre sur la carte. Dans le cas où l'on fournit la date sous une forme textuelle, c'est le type d'encodage des dates du format kml qu'il faut respecter.
- date_fin : date à laquelle cet objet va disparaitre de la carte. Dans le cas où l'on fournit la date sous une forme textuelle, c'est le type d'encodage des dates du format kml qu'il faut respecter.
- geom : objet de géométrie à ajouter. Il s'agit d'objets de type Point, Line, Polygon, ou leurs formes multiple : MultiPoint, MultiLine, MultiPolygon.
- style : identifiant du style à utiliser pour représenter cet objet de géométrie.
- hauteur : permet de définir une hauteur (en mètres) qui sera représentée différemment selon la nature de l'objet de géométrie. L'icone représentant un objet ponctuel sera placé au dessus du sol. Dans le cas des linéaires ou des surfaces, cette hauteur est interprétée comme une épaisseur, c'est à dire que c'est un volume qui sera représenté sur la carte.
addLabel() : ajouter des informations sous forme de texte, en un point donné.
Il est possible de placer du texte sur une position géoréférencée à l'aide de la fonction addLabel(). On peut assimiler cela à un ajout d'objet ponctuel auquel un texte est associé, et d'ailleurs le style d'affichage que l'on peut fournir correspond à un style de type ponctuel tel que l'on peut les définir avec la fonction defIconStyle().
La fonction addLabel() est proposée sous quatre formes différentes. Les deux premières sont équivalentes, il n'y a que la façon de fournir les dates de début et de fin d'affichage qui changent. Les deux suivantes ajoutent la possibilité d'indiquer un dossier dans lequel ces objets seront regroupés :
addLabel(Double posX, Double posY, Double hauteur, String date_debut, String date_fin, String texte, String description, String style)
addLabel(Double posX, Double posY, Double hauteur, Date date_debut, Date date_fin, String texte, String description, String style)
addLabel(String dossier, Double posX, Double posY, Double hauteur, String date_debut, String date_fin, String texte, String description, String style)
addLabel(String dossier, Double posX, Double posY, Double hauteur, Date date_debut, Date date_fin, String texte, String description, String style)
Détail des arguments :
- dossier : identifiant du dossier dans lequel les objets de géométrie seront ajoutés. Si ce dossier n'existe pas encore dans le datafacer, il sera créé automatiquement.
- posX et posY : coordonnées de l'emplacement sur lequel on souhaite positionner le texte. Ces coordonnées doivent bien sûr être exprimées dans le système de coordonnées du projet.
- hauteur : le texte peut être placé en hauteur au dessus du sol, cette hauteur doit être exprimée en mètres.
- date_debut : date à laquelle cet objet va apparaitre sur la carte. Dans le cas où l'on fournit la date sous une forme textuelle, c'est le type d'encodage des dates du format kml qu'il faut respecter.
- date_fin : date à laquelle cet objet va disparaitre de la carte. Dans le cas où l'on fournit la date sous une forme textuelle, c'est le type d'encodage des dates du format kml qu'il faut respecter.
- texte : texte que l'on souhaite afficher sur la carte.
- description : description complémentaire que l'utilisateur pourra consulter en cliquant sur le texte affiché sur la carte.
- style : identifiant du style à utiliser pour représenter cet objet ponctuel. Il s'agit donc d'un style défini à l'aide de la fonction defIconStyle().
add3DModel() : ajouter des objets en 3D
Si le fichier kml ou kmz que l'on produit est destiné à Google Earth, il est possible d'y ajouter des objets en 3D au format Collada (qui portent l'extension .dae) issus par exemple du logiciel Sketchup.
La fonction add3DModel() prévue à cet effet est proposée sous quatre formes différentes. Les deux premières sont équivalentes, il n'y a que la façon de fournir les dates de début et de fin d'affichage qui changent. Les deux suivantes ajoutent la possibilité d'indiquer un dossier dans lequel ces objets seront regroupés :
add3DModel(Double posX, Double posY, Double orientation, Double taille, String date_debut, String date_fin, String modele_dae)
add3DModel(Double posX, Double posY, Double orientation, Double taille, Date date_debut, Date date_fin, String modele_dae)
add3DModel(String dossier, Double posX, Double posY, Double orientation, Double taille, String date_debut, String date_fin, String modele_dae)
add3DModel(String dossier, Double posX, Double posY, Double orientation, Double taille, Date date_debut, Date date_fin, String modele_dae)
Détail des arguments :
- dossier : identifiant du dossier dans lequel les objets 3D seront ajoutés (ce dossier sera affiché dans la légende). Si ce dossier n'existe pas encore dans le datafacer, il sera créé automatiquement.
- posX et posY : coordonnées de l'emplacement sur lequel on souhaite positionner l'objet 3D. Ces coordonnées doivent bien sûr être exprimées dans le système de coordonnées du projet.
- orientation : orientation (en degrés) de l'objet 3D. On doit donc fournir une valeur entre 0.0 et 360.0
- taille : taille relative de l'objet. La valeur 1.0 conserve la taille d'origine. Par exemple 0.5 le rendra deux fois plus petit et 3.5 le rendra trois fois et demi plus grand.
- date_debut : date à laquelle cet objet va apparaitre sur la carte. Dans le cas où l'on fournit la date sous une forme textuelle, c'est le type d'encodage des dates du format kml qu'il faut respecter.
- date_fin : date à laquelle cet objet va disparaitre de la carte. Dans le cas où l'on fournit la date sous une forme textuelle, c'est le type d'encodage des dates du format kml qu'il faut respecter.
- modele_dae : nom (et chemin) du fichier contenant le modèle 3D que l'on souhaite ajouter.
defIconStyle() : définir le style d'icone associé aux objets ponctuels et aux étiquettes
La fonction defIconStyle() permet de spécifier une petite image (icone) que l'on va afficher pour représenter les géométries ponctuelles et les étiquettes (labels). Si aucun style n'est précisé, c'est l'icone par défaut qui sera affiché; dans Google Earth il s'agit de cette épingle jaune : 
La syntaxe de la fonction est la suivante :
defIconStyle(String nom_de_style, String fichier_image, Double taille, Double orientation)
Détail des arguments à fournir :
- nom_de_style : nom que l'on souhaite donner à ce style pour l'identifier. Ce nom sera ensuite utilisé lors de l'ajout de contenu avec des fonctions de type addGeometry().
- fichier_image : nom (et chemin) d'un fichier de type jpg ou png (ce qui est préférable pour les pixels transparents) qui sera utilisé pour représenter les données ponctuelles, ou associé aux étiquettes.
- taille : taille relative de l'image. La valeur 1.0 conserve la taille d'origine. Par exemple 0.5 la rendra deux fois plus petite et 3.5 la rendra trois fois et demi plus grande.
- orientation : orientation (en degrés) de l'image. 0.0 permet d'avoir le haut de l'image orienté vers le nord. En indiquant par exemple 90.0 on oriente le haut de l'image vers l'est, et avec 270.0 il est orienté vers l'ouest.
defStyle() : définir le style d'affichage des lignes et polygones
La fonction defStyle() permet de spécifier la couleur et l'épaisseur du trait des objets linéaires et des bordures de polygone, ainsi que la couleur de la surface interne des polygones.
Deux syntaxes sont disponibles pour cette fonction :
defStyle(String nom_de_style, Double epaisseur_ligne, Color couleur_ligne, Color couleur_surface)
defStyle(String nom_de_style, Double epaisseur_ligne, String couleur_ligne, String couleur_surface)
Détail des arguments à fournir :
- nom_de_style : nom que l'on souhaite donner à ce style pour l'identifier. Ce nom sera ensuite utilisé lors de l'ajout de contenu avec des fonctions de type addGeometry().
- epaisseur_ligne : épaisseur du trait en pixels
- couleur_ligne : couleur du trait. Selon la syntaxe choisie, elle peut être fournie soit avec un tytpe Color d'Ocelet, soit sous la forme textuelle d'encodage de la couleur du format KML.
- couleur_surface : couleur de remplissage de la surface. Selon la syntaxe choisie, elle peut être fournie soit avec un type Color d'Ocelet, soit sous la forme textuelle d'encodage de la couleur du format KML.
defStyleRange() : définir une série indexée de styles pour l'affichage de polygones
La fonction defStyleRange() est semblable à la fonction defStyle() mais permet de produire une série de noms de styles numérotés, chaque style portant une couleur différente pour le remplissage des polygones.
La syntaxe est la suivante :
defStyleRange(String prefixe_du_nom, Double epaisseur_ligne, List<Color> couleurs_surface, Double prop_couleur_ligne)
Détail des arguments à fournir :
- prefixe_du_nom : préfixe du nom que l'on souhaite donner à ce style pour l'identifier. A ce préfixe sera automatiquement ajouté un numéro d'ordre. Par exemple si on fournit "niveau" comme préfixe, on pourra ensuite utiliser les noms de style "niveau1", "niveau2", "niveau3", etc. selon le nombre de couleurs de la liste couleurs_surface.
- epaisseur_ligne : épaisseur du trait en pixels
- couleurs_surface : liste de couleurs pour le remplissage de surface. Le nombre de couleurs présent dans cette liste détermine le nombre de styles qui seront définis dans le datafacer KmlExport, avec un index par style.
- prop_couleur_ligne : la couleur des lignes est produite à partir des couleurs de surface en appliquant un coefficient d'éclaircissement (ou d'assombrissement si le coefficient est négatif). C'est la valeur de ce ceofficient que l'on doit fournir ici. On doit donner une valeur comprise entre -1.0 et 1.0. Par exemple si on donne 0.3, la couleur des lignes sera celle des surfaces mais en 30% plus clair. Avec -0.3 la couleur des lignes sera 30% plus foncé.
remove() : supprimer le fichier
Syntaxe :
remove()
Cette fonction a pour effet de supprimer le fichier kml (ou kmz) pointé par ce datafacer.
saveAsKml(), saveAsKmz() : fonctions d'enregistrement dans un fichier au format kml ou kmz
Deux fonctions sont disponibles selon que l'on préfère enregistrer le contenu du datafacer en kml ou dans sa version compréssée kmz. Et chacune de ces fonctions est proposée avec deux syntaxes différentes :
saveAsKml()
saveAsKml(String nom_de_fichier)
saveAsKmz()
saveAsKmz(String nom_de_fichier)
Les fonctions saveAsKml() et saveAsKmz() sans argument, vont utiliser le nom de fichier utilisé lors de la définition du datafacer (ou le dernier nom fourni avec setFileName()).
Si l'on utilise la version avec un nom de fichier en argument, c'est ce nouveau nom de fichier qui sera utilisé.
setFileName() : changer le nom de fichier d'un datafacer KmlExport
Syntaxe :
setFileName(String nom_de_fichier)
Attention, cela ne fait que modifier le nom du fichier qui sera utilisé lors du prochain appel à une fonction saveAsKml ou saveAsKmz, cela ne modifie en rien les définitions de style ni le contenu qui a été ajouté au datafacer jusque là.
Les fonctions dont le nom commence par set peuvent être utilisées sans le set, comme si on mettait à jour une variable. Ainsi il est équivalent d'écrire :
kmlexp.setFileName("output/newparc.kml")
ou
kmlexp.fileName = "output/newparc.kml"
RasterFile
Type de datafacer permettant la lecture fichiers au format raster. Nous recommandons pour le moment d'utiliser des fichiers au format GeoTiff.
Définition d'un datafacer de type RasterFile
On définit un datafacer RasterFile à l'aide des fonctions :
RasterFile(String nom_de_fichier, String codeEPSG)
RasterFile(String nom_de_fichier)
RasterFile(String nom_de_repertoire, String codeEPSG)
RasterFile(String nom_de_repertoire)
- Le premier argument est le chemin du fichier au format raster. Il peut aussi s'agir d'un chemin de repertoire pouvant contenir plusieurs fichiers raster. Dans ce cas, le premier fichier classé par ordre alphanumérique sera lu.
- Le second argument est l'indication du système de coordonnées utilisé pour les données géographiques contenues dans ce fichier.
Exemple de définition d'un datafacer de type RasterFile
Prenons le cas d'un modèle numérique de terrain (mnt) contenant l'altitude sur chaque pixel. Nous devons d'abord définir une entité qui va porter la propriété qui va avoir la valeur en altitude ainsi qu'une propriété de type "Cell" correspondant à la forme du pixel:
entity MntCellule {
property Cell cell
property Double altitude
}Et la définition du datafacer va faire référence à cette entité (à travers la clause match) :
datafacer Mnt {
data RasterFile("data/mnt25m_ze.tif","EPSG:2975")
match MntCellule {
altitude : "0"
}
}Cette définition de datafacer prépare la lecture d'un fichier au format Geotiff nommé mnt25m_ze.
Dans la clause match on définit la correspondance entre la propriété de l'entité MntCellule : altitude avec le numéro de bande du fichier raster.
Une fois que ce datafacer a été défini, il peut être utilisé dans un scenario.
Utilisation d'un datafacer RasterFile dans un scenario
La première chose à faire est d'affecter une variable avec un nouvel exemplaire (une instance) du datafacer que l'on a défini. Ce qui avec notre exemple peut s'écrire de la façon suivante :
fix mntRaster = new MntreadAll() : lecture d'un fichier RasterFile
Deux formes sont disponibles pour cette fonction :
readAllNom de l'entité spécifiée dans match()
readAllNom de l'entité spécifiée dans match(géométrie__de_découpe)
La première fonction va lire le fichier raster en entier et va construire un nombre d'entités de la catégorie déclarée dans la clause match égal au nombre de pixel du fichier raster, c'est à dire MntCellule dans l'exemple qui précède. Chaque entité contenue dans cette liste sera initialisée avec les valeurs contenues sur une bande du fichier raster en respectant la correspondance spécifiée dans la partie match{...} du datafacer.
Par exemple pour lire les données et obtenir une liste d'entités MntCellule on écrira :
fix liste_cellules = mntRaster.readAllMntCellule // liste_cellules contient une liste d'entités initialisées
// Pour vérifier et savoir combien d'entités MntCellule ont été lues
// on peut par exemple afficher la taille de la liste qui correspondant au nombre de pixels du raster:
println("Nous avons obtenu "+liste_cellules.size+" entités MntCellule.")La deuxième fonction va lire le fichier raster et renvoyer une liste d'entités MntCellule mais en appliquant une découpe selon l'enveloppe de la géométrie passée en paramètre. Par exemple, il peut s'agir d'une propriété de type MultiPolygon d'une entité ou encore de l'enveloppe d'un Shapefile.
setDirectory() : changer de répertoire
Syntaxe :
setDirectory(String chemin_du_répertoire)
Il est possible de changer de répertoire contenant des fichiers rasters en indiquant un nouveau chemin :
mntRaster.setDirectory("data/mntRep")
fix liste_cellules2 = mntRaster.readAllMntCelluleA l'issue de ces deux lignes, liste_cellules2 contient une nouvelle liste d'entités initialisées avec le contenu du premier fichier par ordre alphanumérique du répertoire.
next() : passer au fichier suivant d'un répertoire
Syntaxe :
next()
Si un répertoire a été passé en paramètre lors de la définition du datafacer la fonction next() va placer la prochaine lecture d'entités sur le prochain fichier du répertoire par ordre alphanumérique.
mntRaster.next()
fix liste_cellules2 = mntRaster.readAllMntCelluleupdate() : mettre à jour les propriétés des entités
Syntaxe :
update()
Si un répertoire a été passé en paramètre lors de la définition du datafacer, il est possible de mettre à jour les propriétés des entités définies dans la clause match, par exemple après avoir utilisé la fonction next().
mntRaster.next()
mntRaster.updateDans ce cas les dernières entités MntCellule qui ont été créées avec une fonction readAllMntCellules ont les propriétés mises à jours avec le fichier raster suivant dans le répertoire.
hasNext() : Connaître si un repertoire contient un fichier suivant
Si un répertoire a été passé en paramètre du datafacer, la fonction hasNext() permet de savoir si le répertoire contient un autre fichier par ordre alphanumérique par rapport au fichier actuel.
Syntaxe :
hasNext()
while(mntRaster.hasNext){
mntRaster.next
mntRaster.update
}Dans cet exemple, le datafacer va tester s'il y a un fichier suivant, et tant qu'il y en a, se positionner dessus avec la fonction next() . La mise à jour des entités est ensuite effectuée en appelant la fonction update().
setFileName() : changer le nom du fichier
Syntaxe :
setFileName(String chemin_du_fichier)
Si nous avons un deuxième fichier raster, il est possible de l'utiliser à partir du même datafacer en changeant juste le nom.
mntRaster.setFileName("data/mnt25m_ze2.tif")
fix liste_cellules2 = mnt.readAllMntCelluleA l'issue de ces deux lignes, liste_cellules2 contient une nouvelle liste d'entités initialisées avec le contenu du nouveau fichier passé en paramètre.
Si un répertoire a été passé en paramètre lors de la définition du datafacer, le fichier avec le chemin passé en paramètre sera sélectionné. Dans ce cas, la fonction next() permettra de se placer sur le prochain fichier à partir de celui-ci.
getBoundaries() : Obtenir l'enveloppe du raster sous forme de Polygon
Syntaxe :
getBoundaries()
La fonction retourne un Polygon qui représente l'enveloppe du fichier raster. Ce polygone peut, par exemple servir de découpe en lisant un autre fichier raster dont l'enveloppe est plus grande.
let polygon = mntRaster.getBoundaries()
fix liste_cellules2 = mntRaster2.readAllMntCellule(polygon)A l'issue de ces deux lignes, liste_cellules2 contient une nouvelle liste d'entités initialisées avec le contenu du nouveau fichier raster découpé selon l'enveloppe du datafacer.
setFileFormat() : Spécifier l'extension des fichiers à lire
Syntaxe :
setFileFormat(String extension_du_fichier)
La fonction sélectionne les fichiers dont l'extension a été passée en paramètre. L'extension doit être spécifiée par un type String qui commence par un ".", par exemple ".tif".
let polygon = mntRaster.setDirectory("data/mntRep")
mntRaster.setFileFormat(".tif")A l'issue de ces deux lignes, seuls les fichiers au format ".tif" seront lus en cas d'usage de la fonction next().
RasterExport
Datafacer servant à exporter une liste d'entités cellulaires dans un fichier raster, actuellement au format GeoTiff.
Définition d'un datafacer de type RasterExport
Le datafacer RasterExport s'instancie directement dans le scénario :
let rasterExport = new RasterExport()Exemple d'utilisation d'un datafacer de type RasterExport
Prenons le cas d'une entité caractérisée spatialement par une propriété Cell et dont la propriété altitude contient la valeur en altitude issue d'un MNT. L'entité est définie de la manière suivante :
entity MntCellule {
property Cell cell
property Double altitude
}export() : enregistrer un fichier au format raster
Syntaxe :
export(liste_entité_cellule, chemin_sortie, EPSG, propriété_entité_à_exporter)
En considérant une liste_cellules une liste contenant des MntCellules avec une valeur en altitude. En utilisant le datafacer RasterExport nous pouvons spécifier la propriété de nos entités MntCellule que nous voulons enregistrer au format geotiff :
let rasterExport = new RasterExport
rasterExport.export(liste_cellules, "output/monMnt.tif","EPSG:2975", "altitude")A l'issue de ces deux lignes un fichier raster nommé "monMnt.tif" avec une bande contenant les valeurs en altitude pour chaque entités de _listecellules a été créé dans le répertoire output.
GraphMLExport
Ce datafacer permet la production et l'enregistrement de graphes au format GraphML. Ce format est utilisé par de nombreux logiciels d'affichage et manipulation de graphes (comme Gephi ou Yed), mais aussi par des bibliothèques de fonctions (comme GraphIO.jl en Julia ou pygraphml en Python par exemple).
Définition d'un datafacer de type GraphMLExport
On a le choix entre définir d'abord un datafacer à l'aide du mot clé datafacer puis créer une instance de cette définition dans le scénario. Ou créer directment une instance de GraphMLExport dans le scnénario.
Pour la première méthode on définit d'abord un datafacer de la manière suivante :
datafacer DGrml {
data GraphMLExport("output/mongraphe.graphml)
}Puis on l'instancie dans le scérario :
fix grml = new DGrmlPour la seconde méthode on instancie directement GraphMLExport dans le scenario :
fix grml = new GraphMLExport()ou en fournissant aussi un fichier d'exportation :
fix grml = new GraphMLExport("output/monGraphe.graphml")L'instance de GraphMLExport ainsi créée correspond à un graphe vide. Si on l'enregistre tel quel (avec grml.save) on obtient un fichier qui contient ceci :
<?xml version="1.0" encoding="UTF-8"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns
http://graphml.graphdrawing.org/xmlns/1.1/graphml.xsd">
</graphml>Pour y ajouter du contenu, on utilise des fonctions permettant d'ajouter un graphe (ou plusieurs), des noeuds, des arêtes, et éventuellement des propriétés attachées à ces différents éléments.
La première chose à faire est donc d'ajouter au moins un graphe :
graph() : ajout d'un graphe
Cette fonction ajoute un graphe (vide à ce stade) et retourne un identifiant de graphe dont on aura besoin pour y ajouter du contenu. Le format GraphML permet d'avoir plusieurs graphes dans un même fichier, et chaque graphe a un identifiant qui permet de les distinguer.
Il est aussi possible d'emboiter une graphe dans un noeud d'un autre graphe. Il faut pour cela indiquer l'identifiant du noeud dans lequel on souhaite placer un graphe.
Plusieurs formes sont disponibles pour la création de graphe :
String graph(): ajoute un graphe et retourne son identifiant.
String graph(node_id): ajoute un graphe dans le noeud identifié parnode_idet retourne l'ìdentifiant du graphe créé.
Ce deux premières formes produisent des graphes non orientés. On peut créer des graphes orientés avec les fonctions :
String directedGraph(): ajoute un graphe orienté et retourne son identifiant.
String directedGraph(node_id): ajoute un graphe orienté dans le noeud identifié parnode_idet retourne l'ìdentifiant du graphe créé.
Dans l'exemple qui suit on crée une instance de GraphMLExport et on y ajoute un graphe, puis on sauve le resultat dans un fichier :
fix grml = new GraphMLExport("output/monGraphe.graphml")
g_id = grml.graph
grml.saveLe fichier produit contient ceci (on a remplacé les informations de l'en-tête par ... pour faciliter la lecture) :
<?xml version="1.0" encoding="UTF-8"?>
<graphml ... >
<graph edgedefault="undirected" id="g1"/>
</graphml>
node() : ajout d'un noeud
Deux fonctions sont disponibles pour ajouter un noeud à un graphe :
String node(graph_id): ajoute un noeud au graphe désigné par l'identifiantgraph_idfourni en argument. Cette fonction génère un identifiant de noeud et retourne cet identifiant.
String node(graph_id, node_id): ajoute un noeud au graphe désigné par l'identifiantgraph_idfourni en argument. Cette fonction utilise l'identifiant de noeudnode_idfourni en second argument et retourne cet identifiant.
Voici un exemple où l'on crée un premier noeud sans fournir d'identifiant, puis un deuxième où on fournit l'identifiant "node_b" :
fix grml = new GraphMLExport("output/monGraphe.graphml")
fix g_id = grml.graph
fix n_ida = grml.node(g_id)
fix n_idb = grml.node(g_id,"node_b")
grml.saveLe fichier GraphML produit contient ceci :
<?xml version="1.0" encoding="UTF-8"?>
<graphml ... >
<graph edgedefault="undirected" id="g1">
<node id="n2"/>
<node id="node_b"/>
</graph>
</graphml>
edge() : ajout d'une arête
Deux fonctions sont diponibles pour ajouter une arête à un graphe :
String egde(graph_id, source_node_id, target_node_id): ajoute une arête au graphe désigné par l'identifiantgraph_idfourni en argument. Cette arête va relier les deux noeuds dont les identifiants sont fournis en arguments. Cette fonction génère un identifiant d'arête et retourne cet identifiant.
String egde(graph_id, source_node_id, target_node_id, edge_id): ajoute une arête au graphe désigné par l'identifiantgraph_idfourni en argument. Cette arête va relier les deux noeuds dont les identifiants sont fournis en arguments. Cette fonction utlise l'identifiant d'arêteedge_idet retourne cet identifiant.
Si le graphe ne contient pas encore de noeud avec les identifiants fournis (source_node_id ou target_node_id) alors ces noeuds seront automatiquement céés et ajoutés au graphe. Il est donc possible d'ajouter un ensemble de noeuds en ajoutant des arêtes ayant ces noeuds comme extrémités, sans avoir besoin d'ajouter ces noeuds au préalable.
Voici un exemple de création de noeuds et d'arêtes :
fix grml = new GraphMLExport("output/monGraphe.graphml")
fix g_id = grml.graph
fix n_ida = grml.node(g_id)
fix n_idb = grml.node(g_id,"node_b")
fix e_idc = grml.edge(g_id,n_ida,n_idb)
fix e_idd = grml.edge(g_id,n_idb,"node_c")
grml.saveLors de la création de la deuxième arête, il est fait référence à un noeud "node_c" qui n'est pas encore présent dans le graphe. On pourra constater que celui-ci a étée ajouté automatiquement.
Le fichier GraphML produit contient ceci :
<?xml version="1.0" encoding="UTF-8"?>
<graphml ... >
<graph edgedefault="undirected" id="g1">
<node id="n2"/>
<node id="node_b"/>
<edge id="e3" source="n2" target="node_b"/>
<node id="node_c"/>
<edge id="e4" source="node_b" target="node_c"/>
</graph>
</graphml>
attribute() : ajout d'un attribut et de sa valeur
Les attributs sont des couples (nom,valeur) que l'on peut attacher à un graphe, un noeud ou une arête. Tout comme les autres éléments, les attributs possèdent un identifiant uniaue qui peut soit être généré, soit fourni lors de la création.
Attention, lorsque l'on demande à attacher un attribut à un élément, il faut que cet élément ait déjà été ajouté dans le datafacer GraphMLExport sans quoi, ne sachant pas à quoi le rattacher, la fonction ne fait rien.
Deux fonctions sont disponibles pour ajouter un attribut à un élément :
String attribute(eln_id, name, value): ajoute un attribut à l'élément désigné par son identifianteln_id(il peut s'agir d'un graphe, un noeud ou une arête). Cette fonction génère un identifiant pour cet attribut et retourne cet identifiant.
String attribute(eln_id, name, value, at_id): ajoute un attribut à l'élément désigné par son identifianteln_id(il peut s'agir d'un graphe, un noeud ou une arête). Cette fonction utilise l'identifiant d'attributat_idqui est fourni en dernier argument.
Par exemple pour ajouter un attribut de couleur à un noeud dont l'identifiant est node_c cela peut s'écrire de la façon suivante :
fix atid1 = grml.attribute("node_c","color","red")Valeur par défaut des attributs
Quand on attache un attribut avec son nom et sa valeur à un élément comme un noeud ou une arête, les logiciels qui liront le fichier graphlm peuvent s'attendre à ce que tous les noeuds ou toutes les arêtes portent aussi un attribut du même nom avec une valeur.
Pour ne pas être obligé de définir ces valeurs partout on peut fournir une valeur par défaut à l'aide de la fonction :
setAttributeDefault(at_id,defaultValue): permet de fournir une valeur par défaut pour tous les attributs similaires à celui dont l'identifiantat_idest fourni en argument. Par "similaire" on entend les attributs qui portent le même nom et qui sont attachès au même type d'élément (graphe, noeud ou arête).
Dans la suite de l'exemple précédent on pourrait définir une couleur par défaut pour tous les noeuds du graphe avec :
grml.setAttributeDefault(atid1,"white")