Datafacer
In Ocelet, a datafacer is to establish a link between data and the objects manipulated in a model.
This new word has been obtained from the words Data and Interface.
Different datafacers are available for specific data formats.
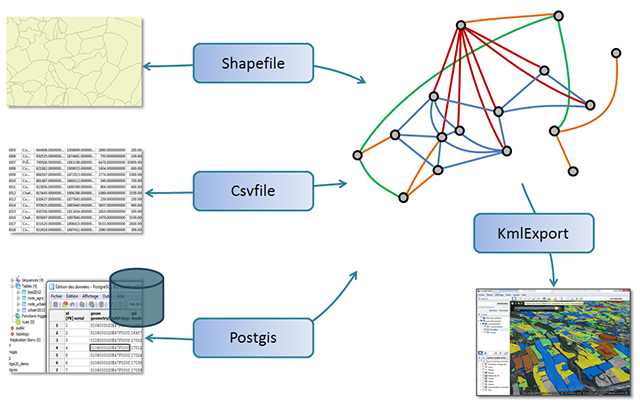
Each datafacer needed has to be defined and parameterised before being used in a scenario. All the datafacers have a common minimal syntax for a basic definition, but their parameterisation will depend largely on the type of datafacer, that is, the data format for which it is specialised.
In fact, two categories of data formats will be used: those comparable to a table (with lines and columns) and those that are not structured in that way. For those with table-like formats (Shapefile, relational database, spread sheet (csv file)) the definitions and functions available are largely similar.
The first section of this documentation provide indications on the syntax common to all datafacers, and also those found in table-like formats. Subsequent sections are for each of the other specific data formats.
Content
Generic syntax
Datafacer definition
datafacerdatafacer name{datadatafacer type(parameters for data source or destination)
content specific to each datafacer type}
The name of the datafacer must begin with a letter (preferably upper case) but can eventually be followed by numbers, and not contain blanks or special characters.
Tabular data format
In the present version of Ocelet, the following formats are considered table-like:
These data storage formats have in common a structure with one record per line and a property (or attribute) per column.
We have used this structure to facilitate the creation of a series of entities (one per record) and an automatic initialisation of their properties from the contents of the columns. It is only necessary to give the correspondence between properties of entities and columns of the data table.
The syntax for specifying this correspondence is as follows:
datafacerdatafacer name{datatype of datafacer(parameters for the data source or destination)matchentity type{
property:"column name"
property:"column name"
...
property:"column name"}}
Note that for csv files, the first line has to contain the column names that will be used in the match clause.
Here is a first example of a csv file:
entity MyEntity {
property Integer id
property String name
property Integer pop
}
datafacer CsvData {
data Csvfile("data/mydatafile.csv")
match MyEntity {
id : "gid"
nom : "country"
pop : "population"
}
}In this example, a series of entities MyEntity are obtained (one entity per line in the csv file) initialised with the content of the columns gid, country and population.
Using it in a scenario
In a scenario, we start by creating a variable to contain one datafacer (this can be done several times if more datafacers are necessary), then we use it to call the predefined functions. For most of them the functions are specific to each type of datafacer.
The table-like datafacers have in common the following function:
List<MyEntity> readAll_MyEntity_(): Builds a list of entities of type MyEntity. Each entity of that list has been initialised with the values of a line in the data table according to the correspondence specified in the match{...} part of the datafacer.
Complementing the previous example, if the mydatafile.csv file contains the following values:
gid;country;population
1;France;66000000
2;Spain;47000000
3;Portugal;10000000A list of 3 entities can be obtained using the following instructions:
let cvsdataf = new CsvData
let myEntities = csvdataf.readAllMyEntity() Each element of the list myEntities will be a an entity of type MyEntity whose properties are taken from the values of a line of the file.
Read data into a KeyMap
With the Csvfile, Postgis et Shapefile datafacers, there is also a readToKeyMap(String keypropertyname) function that allows to read data directly into a KeyMap.
Like for readAll() each line record will give the instance of an entity. The entity is added to a KeyMap, associated with a key which the property value given as parameter.
Therefore, it must be ensured that the property chosen as key contains only unique values, because otherwise, entities with the same key values will be overwritten in the KeyMap.
Example
entity Parc {
property Integer id
property MultiPolygon geom
property String own
}
datafacer Dplots {
data Shapefile("data/AgPlots.shp","EPSG:32740")
match Parc {
id: "PID"
geom : "geom"
own : "OWNER"
}
scenario MyModel {
fix dplots = new Dplots
fix plotsbyid = dplots.readToKeyMap("id")
println(""+plotsbyid.get(4))
}Coordinate system for a model
It is possible to specify the coordinate reference system for a model directly, without the need to read it from a data file.
setModelCRS(String epsgcode)It can be used in a scenario either like this:
setModelCRS("EPSG:32740")or like this:
modelCRS = "EPSG:32740"Csvfile
Type of datafacer for reading text files whose fields are separated with a comma (comma separated values : csv). The semicolon ; is the default separator, but it is possible to specify another one.
This type of file can be obtained using a simple text editor, or be exported from a spread sheet.
Here is a small file in csv format that will be used in the example codes in this section:
num;country;surface;population
1;Mauritius;2040;1260000
2;Madagascar;587040;23813000
3;Seychelles;455;91650
4;Comores;2236;767000It is important to note that the first line of the file contains the names of the columns. These comumn names must be given in the first line of the file as they are used in the definition of the datafacer.
Definition of a Csvfile type datafacer
The construction function used to define a datafacer of this type can be used in two ways:
Csvfile(String File_name)
Csvfile(String File_name, String separator)
In both cases, the file name must contain the path to access the file.
If another separator is specified, it will be used instead of the semicolon to separate the values of a line.
Note: The first line of the csv file must contain the names of the columns.
Example of a Csvfile type datafacer
datafacer CsvData {
data Csvfile("data/mydatafile.csv")
match Country {
id : "num"
name : "country"
pop : "population"
}
}This example assumes that an entity type Country has been defined elsewhere:
entity Country {
property Integer id
property String name
property Double pop
}This definition of the datafacer prepares the file for Read or Write with values separated by the default ;. But if the values were separated by | for example, this needs to be specified in the definition of the datafacer: data Csvfile("data/mydatafile.csv","|").
Note that it is not necessary to establish a correspondance with all the columns of the table in the csv file. In this example, the Country entity has three properties whiel the file has four data columns. The column of surface area was not required and was thus unused in the definition of the datafacer.
Once defined, the datafacer can be used in a scenario.
Using the Csvfile datafacer in a scenario
First, a variable need to be assigned with a copy (an instance) of the datafacer defined. In the present example, this is written as follows:
fix csvdat = new CsvDataThen, usual functions specific to the Csvfile datafacers can be called, to read or write data, or to change the name of the file.
append() : write in a csv file
To add a single line to the file, we can use the function:
append(Entity entity_to_write)
The Entity type indicated here must be understood as the entity type declared in the match clause in the definition of the datafacer.
Example:
csvdat.append(new Country=>[id=8 name="Mozambique" pop=25900000.0])This creates a new Country entity initialised with data on Mozambique, and adds a line at the end of the csv file with these data.
To add several lines at one go, the same function can be used, but with a list of entities:
append(List<Entity> list_of_entites_to_be_added_to_the_file )
Here also, the Entity type indicated must be understood as the entity type declared in the match clause in the definition of the datafacer.
readAll() : read a csv file
This function can be used in two ways:
readAll()
readAllEntity name specified in match()
Both functions create a list of entities of the type declared in the match clause, that is Country in the present example. Each entity of the list has been initialised with data from one line of the table according to the correspondence specified in the match{...} part of the datafacer.
For example, reading data and producing a list of entities is done as follows:
fix list_countries = csvdat.readAll // list_countries contains a list of entities already initialised
// As verification, the content read can be be displayed using:
for (country:list_countries) println(country.name+" population:"+country.pop)In this example, an equivalent result would have been obtained with:
fix list_countries = csvdat.readAllCountry
remove() : delete the file
Syntax:
remove()
This function will delete the csv file to which the datafacer points.
If the file does not exist, nothing happens and no error message is generated. A call to a remove() before an append() will ensure that records will not be added to an existing file.
csvdat.setFilename("output/Results.csv")
csvdat.remove
csvdat.append(listResults)In this example, a new file Results.csv is created that will contain nothing else but the entities of listResults.
setFileName() : change file name
Syntax:
setFileName(String file_name)
If we have another csv file structured like the first one (that is with the same types and column names), it can be used with the same datafacer, just by changing the name.
csvdat.setFileName("data/myOtherdatafile.csv")
fix list_countries2 = csvdat.readAllAfter these two lines, list_countries2 contains a new list of entities intialised with the content of the other file.
The functions whose names start with set can be used without the set, as if a variable is being updated.
Here, we can also write: csvdat.fileName = "data/myOtherdatafile.csv" to obtain the same result.
setSeparator() : change the separator
It is possible to change the separator character declared for a Csvfile datafacer. This may be useful when reading a file that uses a given separator, and writing data (from the same entity type) into another file with a different separator, without having to define another datafacer.
The following function is used:
setSeparator(String new_separator)
Example:
csvdat.setSeparator(",")Functions whose names start with set can be used without the set, as if a variable is being updated.
Here, we can write: csvdat.separator = "," to obtain the same result.
Shapefile
A type of datafacer to read and write files in the ESRI Shapefile format. More information on this file format is available in Wikipedia or in the ArcGIS documentation.
For the needs of this documentation, please note that data saved in shapefile format are in fact stored in at least three files (with extensions shp, shx and dbf). All three files are required to ensure the coherence of the data. In practice, reference is made only to the file with the shp extension, but the two other files are implicitly present.
Definition of the Shapefile datafacer
The Shapefile datafacer is defined with the following function:
Shapefile(String file_name, String EPSGcode)
- The first argument is simply the name (and path) of the file with the
.shpextension. - The second argument sets the coordinate system used for the geographical data stored in the file. Instead of giving details of all the parameters required to define the datum and the geographical projection, we use the corresponding EPSG code. For example, data for Reunion Island are generally given in the RGR92 system (Référentiel Géographique de la Réunion), and the corresponding EPSG code is "EPSG:2975".
Example of the definition of a Shapefile datafacer
In the case of a plot map (agricultural, cadastral or other), we need to first prepare an entity that will hold the properties of the plots:
entity Plot {
property Integer id
property Integer landcover
property Double surface
property String owner
property MultiPolygon geom
}and to define a datafacer that will refer to this entity (through the match clause):
datafacer Plotmap {
data Shapefile("data/AgPlots.shp","EPSG:2975")
match Plot {
id : "pid"
landcover : "lct"
geom : "the_geom"
}
}This datafacer definition prepares the AgPlots shapefile for Read or Write. Only the .shp file is given, but in Read mode, the two files AgPlots.shx and AgPlots.dbf must be located in the same folder. In Write mode, if the files do not exist yet, all three of them are created when the file is saved.
In the match clause, the correspondance between the properties of the Plot entity: id, landcover, geom ... and the attribute names (or column names) of the shapefile: "pid", "lct", "the_geom" ... is defined.
The "the_geom" attribute refers to the geometric shape contained in the record. It can be a point, line or polygon, or (as often) the same in their multiple form: multipoint, multiline or multipolygon.
In order to check the content of a shapefile, the about() function of the datafacer may be used.
Once the datafacer is defined, it can be used in a scenario.
Using a Shapefile datafacer in a scenario
First, a variable need to be assigned with a copy (an instance) of the datafacer defined. In the present example, this is written as follows:
fix dataplot= new PlotmapThen, usual functions specific to the Shapefile datafacers can be called, to read or write data, or to change the name of the file.
about() : what is in the shapefile ?
When we do not know exactly what are the types of the attributes in the shapefile, or how the names of the attributes are spelled (to be able to use them in the match clause for example), the about() function can be used to provide these informations.
This function gives an overview of what information Ocelet will be able to read from the shapefile. The syntax is as follows:
String about()
In other words, the about function of the shapefile datafacer will return a text that can be displayed.
This is an example of how the function is used. It also shows that the match clause is not compulsory in the definition of a Shapefile datafacer:
scenario Shp_Aboutdemo {
fix dataplot = new Plotmap
println(dataplot.about())
}
datafacer Plotmap {
data Shapefile("data/AgPlots.shp","EPSG:2975")
}In this example, parentheses have been put: dataplot.about(), but as no arguments are required by the function, these parentheses are optional. dataplot.about can be used to give the same result.
The execution of the scenario of this example will send the following to the console:
Shapefile : AgPlots
Contains 678 records.
Coordinate reference system : WGS_1984_UTM_Zone_40S
Bounds : 363007.54725825915 7645776.8813113645 , 368557.25827995676 7652774.407732953
Description of the 7 attributes :
[1] : the_geom : MultiPolygon
[2] : ALT_M : Double
[3] : SURF : Double
[4] : PID : Integer
[5] : OWNER : String
[6] : LCT : Integer
[7] : LASTFALLOW : Integerappend() : writing in a shapefile
To add a single line to the file, we can use the function:
append(Entity entity_to_write)
The Entity type indicated here must be understood as the entity type declared in the match clause in the definition of the datafacer.
Example:
let p5 = list_plot.get(5)
p5.owner = "David"
dataplot.append(p5)This records in the shapefile the entity passed on through append().
To add several lines at one go, the same function can be used, but with a list of entities:
append(List<Entity> list_of_entites_to_be_added_to_the_file )
Here also, the Entity type indicated must be understood as the entity type declared in the match clause in the definition of the datafacer.
In the case when the shapefile does not exist yet, it is created and the records are added. In the case when the shapefile already exists, the records are added after those already present.
Beware when records are added to an existing shapefile, the names of the columns, their number and their types must be identical to those of the existing shapefile.
readAll() : reading a shapefile
This function can be used in two ways:
readAll()
readAllEntity name specified in match()
Both functions are equivalent. They create a list of entities of the type declared in the match clause, that is Plot in the present example. Each entity of the list has been initialised with data from the shapefile according to the correspondance specified in the match{...} part of the datafacer.
For example, reading data and producing a list of Plot entities is done as follows:
fix list_plot = dataplot.readAll // list_plot contains a list of entities initialised
// As verification, and to know how many records have been read
// we can for example display the size of the list:
println("We have obtained "+list_plot.size+" Plot entities.")In this example, an equivalent result would have been obtained with:
fix list_plot = dataplot.readAllPlot
remove() : delete the shapefile
Syntax:
remove()
This function will delete the shapefile and its associated files (.shp, .shx, .dbf).
If the file does not exist, nothing happens and no error message is generated. A call to a remove() before an append() will ensure that records will not be added to an existing file.
dataparc.setFilename("output/Results.shp")
dataparc.remove
dataparc.append(listPlots)In this example, a new file Results.shp is created that will contain nothing else but the entities of listPlots.
setFileName() : change file name
Syntax:
setFileName(String file_name)
If we have another shapefile file structured like the first one (that is with the same types and column names), it can be used with the same datafacer, just by changing the name.
dataplot.setFileName("data/AgPlots_2.shp")
fix list_plot2 = dataplot.readAllAfter these two lines, list_plot2 contains a new list of entities intialised with the content of the other file.
The functions whose names start with set can be used without the set, as if a variable is being updated.
Here, we can also write: dataplot.fileName = "data/AgPlot_2.shp" to obtain the same result.
Postgis
Type of datafacer for reading and writing records in a Postgresql database with the PostGIS spatial extension.
Definition of a Postgis datafacer
The Postgis datafacer is defined with the following function:
Postgis(String server, String port, String base, String schema, String table, String user, String password, String EPSGcode)
Détail des arguments à fournir :
- server : address of the database server. If the server is installed on the same computer as Ocelet, this address will be "localhost"
- port : port number to access the server. The default value is "5432".
- base : name of your database
- schema : name of the schema where the table is located
- table : name of the table to be accessed
- user : user identification for this database
- password : password of the user for this database
- EPSGcode : indicates the coordinate system used for the geographical data stored in the file. Instead of giving details of all the parameters required to define the datum and the geographical projection, we use the corresponding EPSG code. For example, data for Reunion Island are generally given in the RGR92 system (Référentiel Géographique de la Réunion), and the corresponding EPSG code is "EPSG:2975".
Example of the definition of a Postgis datafacer
In the case of a plot map (agricultural, cadastral or other), we need to first prepare an entity that will hold the properties of the plots:
entity Plot {
property Integer id
property Integer landcover
property Double surface
property String owner
property MultiPolygon geom
}and to define a datafacer that will refer to this entity (through the match clause):
datafacer BasePlotmap {
data Postgis("localhost","5432","MyOceletBase","public","AgPlots","user","password","EPSG:2975")
match Plot {
id : "pid"
owner : "owner"
landcover : "lct"
geom : "the_geom"
}
}This datafacer definition prepares the public.AgPlots table for Read or Write. (public is the name of the schema) belonging to the MyOceletBase database.
In the match clause, the correspondence between the properties of the Plot entity: id, landcover, geom ... and the attribute names (or column names) of the shapefile: "pid", "lct", "the_geom" ... is defined.
The "the_geom" attribute refers to the geometric shape contained in the record. It can be a point, line or polygon, or (as often) the same in their multiple form: multipoint, multiline or multipolygon.
In order to check the nature of the geometries in a table of the database, the about() function of the datafacer may be used.
Once the datafacer is defined, it can be used in a scenario.
Using a Postgis datafacer in a scenario
First, a variable need to be assigned with a copy (an instance) of the datafacer defined. In the present example, this is written as follows:
fix dataplot= new BasePlotmapThen, usual functions specific to the Postgis datafacers can be called, to read or write data.
about() : what is in the table?
When we do not know exactly what are the types of the attributes in the table (from an Ocelet point of view), or how the names of the attributes are spelled (to be able to use them in the match clause for example), the about() function can be used to provide these informations.
This function gives an overview of what information Ocelet will be able to read on the structure of the table concerned. The syntax is as follows:
String about()
In other words, the about function of the Postgis datafacer will return a text that can be displayed.
This is an example of how the function is used:
scenario Postgis_Aboutdemo {
fix dataplot = new Plotmap
println(dataplot.about())
}
datafacer Plotmap {
data Postgis("localhost","5432","MyOceletBase","public","AgPlots","postgres","postgres","EPSG:2975")
}In this example, parentheses have been put: dataplot.about(), but as no arguments are required by the function, these parentheses are optional. dataplot.about can be used to give the same result.
The execution of the scenario of this example will send the following to the console:
Table : AgPlots
Contains 678 records.
Coordinate reference system : EPSG:RGR92 / UTM zone 40S
Bounds : 363007.53125 7645776.5 , 368557.28125 7652774.5
Description of the 7 attributes :
[1] : geom : MultiPolygon
[2] : alt_m : Double
[3] : surf : Double
[4] : pid : Integer
[5] : owner : String
[6] : lct : Integer
[7] : lastfallow : Integerappend() : writing records in a table of the Postgis base
To add a single line to the table, we can use the function:
append(Entity entity_to_write)
The Entity type indicated here must be understood as the entity type declared in the match clause in the definition of the datafacer.
Example:
let p5 = list_plot.get(5)
p5.owner = "David"
dataplot.append(p5)This records in the table the entity passed on through append().
To add several lines at one go, the same function can be used, but with a list of entities:
append(List<Entity> ist_of_entites_to_be_added)
Here also, the Entity type indicated must be understood as the entity type declared in the match clause in the definition of the datafacer.
In the case when the table does not already exist in the database, it is created (provided you have the rights for creation and writing) and the records are added. In the case when the table already exists, the records are added after those already present.
Beware when records are added to an existing table, the names of the columns, their number and their types must be identical to those of the existing table.
readAll() : read records from a Postgis table
This function can be used in two ways:
readAll()
readAllEntity name specified in match()
Both functions are equivalent. They create a list of entities of the type declared in the match clause, that is Plot in the present example. Each entity of the list has been initialised with data from a record in the table according to the correspondence specified in the match{...} part of the datafacer.
For example, reading data and producing a list of Plot entities is done as follows:
fix list_plot = dataplot.readAll // list_parc contains a list of entities initialised
// As verification, and to know how many records have been read
// we can for example display the size of the list:
println("We have obtained "+list_plot.size+" Plot entities.")In this example, an equivalent result would have been obtained with:
fix list_plot = dataplot.readAllPlot
remove() : delete the table
Syntax:
remove()
This function will delete from the database the table to which the datafacer points.
KmlExport
Type of datafacer for reading and writing files in KML (Keyhole Markup Langage) format, that can be opened and displayed with several GIS software and virtual globes. In particular, this format is used in Google Earth which accepts kml time tags and offers the possibility of displaying dynamic maps.
Definition of a KmlExport datafacer
The KmlExport datafacer is defined with the following function:
KmlExport(String nom_de_fichier)
The only argument required is the name (and path) of the kml file to be produced.
Exemple of the definition of a KmlExport datafacer
datafacer KmlExp {
data KmlExport("output/plotmap.kml")
}This definition prepares writing a kml file in the output folder of the project.
Using a KmlExport datafacer in a scenario
In a scenario this type of datafacer is used in four steps:
- Assign a variable with a copy (an instance) of the datafacer
- Add definitions of rendering styles (colours, line thickness, etc.)
- Add content.
- Save the file in kml or kmz format.
The assignment of the variable is written as follows:
fix kmlexp = new KmlExpRendering styles definition is made using the defIconStyle(), defStyle() and defStyleRange() functions that are detailed below.
Content can be added using the following addFolder(), addGeometry(), addLabel() and add3DModel() functions that are detailed below.
Finally, the actual saving of the file is done using either saveAsKml() or saveAsKmz() according to the format chosen.
The kml format is in text format based on XML. It can eventually be read (and modified manually) with a text editor. The kmz format is simply a zipped version of the kml: the content is identical, the file size is reduced, but it cannot be read or modified using a text editor.
In sum, below is a minimal example to produce a kml file in four steps:
scenario Kml_example {
fix dataplot = new Plotmap
fix list_plot = dataplot.readAllPlot
// step 1 : Assign a variable with new kml datafacer
fix kmlexp = new KmlExp
// step 2 : Add rendering styles definitions
kmlexp.defStyle("greenstyle",1,Color|rgb(0,128,64),Color|rgb(128,255,128))
// step 3 : Add content
for (plot:list_plot) {
kmlexp.addGeometry("","","",plot.geom,"greenstyle",0)
}
// step 4 : Actual file saving (in kml format)
kmlexp.saveAsKml
}
datafacer KmlExp {
data KmlExport("output/plotmap.kml")
}
entity Plot {
property Integer id
property Integer landcover
property Double surface
property String owner
property MultiPolygon geom
}
datafacer Plotmap {
data Shapefile("data/AgPlots.shp","EPSG:2975")
match Plot {
id : "PID"
landcover : "LCT"
owner : "owner"
geom : "the_geom"
}
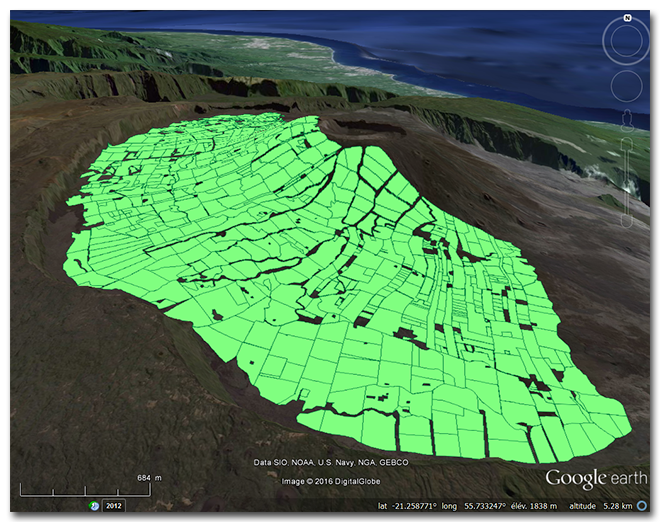
}The output/plotmap.kml file produced in this example can then be displayed in Google Earth and looks like this:
addFolder() : regroup several geographical information layers in a folder
The kml format allows creating several layers that can individually be toggle displayed when represented on a map. In order to toggle display a many of them simultaneously, they can be grouped in folders. In Google Earth, the folders and their content are visible in the Places panel. The addFolder() function will add a new (empty) folder in a kmlExport datafacer:
addFolder(String folder_name, Date date_start, Date date_end)
addFolder(String folder_name, String date_start, String date_end)
Argument details:
- folder_name: identifier of the folder to be created
- date_start: date when folder content is displayed on the globe
- date_end: date when folder content disappears from the globe
The addFolder() function is not the only way to add a folder to a datafacer. This can be done directly with certain versions of the addGeometry() function.
addGeometry() : add points, lines and polygons
The addGeometry() function allows adding different geometrical object shapes (point, linear or surface) to the content of a datafacer.
This function can be used in different ways. The first two are equivalent, with only the (begin and end) date formats that change. The other two will add the possibility of regrouping object types in separate folders:
addGeometry(String identifier, String date_start, String date_end, Geometry geom, String style, Double height)
addGeometry(String identifier, Date date_start, Date date_end, Geometry geom, String style, Double height)
addGeometry(String folder, String identifier, String date_start, String date_end, Geometry geom, String style, Double height)
addGeometry(String folder, String identifier, Date date_start, Date date_end, Geometry geom, String style, Double height)
Argument details :
- folder: identifier of folder to which the geometrical objects will be added. If the folder does not exist, it will automatically be created.
- identifier: identifier of objets that will appear in the Places panel.
- date_start: date when folder content is displayed on the globe. In case date is in text format, this is the kml format date encoding type to be used.
- date_end: date when folder content disappears from the globe. In case date is in text format, this is the kml format date encoding type to be used.
- geom: geometrical object to be added. The objects are of Point, Line, Polygon type, or of their multiple forms: MultiPoint, MultiLine, MultiPolygon.
- style: style identifier to be used to represent a geometrical object.
- height: allows specifying a height (in metres) that will be used differently for the represention of the different object types. For linear or surface objects, the height is taken as a thickness, which means that a volume will be shown on the map.
addLabel() : add text information at a given point in space
It is possible to place a text at a georeferenced location using the addLabel() function. This can be assimilated to the addition of a point geometry to which a text is associated. Besides, the display style corresponds to a point style as can be defined with the defIconStyle() function.
The addLabel() function is proposed with four different usage. The first two are equivalent, with only the (begin and end) date formats that change. The other two will add the possibility of regrouping object types in separate folders:
addLabel(Double posX, Double posY, Double height, String date_start, String date_end, String text, String description, String style)
addLabel(Double posX, Double posY, Double height, Date date_start, Date date_end, String text, String description, String style)
addLabel(String folder, Double posX, Double posY, Double height, String date_start, String date_end, String text, String description, String style)
addLabel(String folder, Double posX, Double posY, Double height, Date date_start, Date date_end, String text, String description, String style)
Argument details:
- folder: identifier of folder to which the geometrical objects will be added. If the folder does not exist, it will automatically be created.
- posX and posY: coordinates of the location where the text will be placed. These coordinates are of course defined in the coordinate system of the project.
- height: the text can be placed above the ground. Height is expressed in metres.
- date_start: date when folder content is displayed on the globe. In case date is in text format, this is the kml format date encoding type to be used.
- date_end: date when folder content disappears from the globe. In case date is in text format, this is the kml format date encoding type to be used.
- text: text to be displayed on the map.
- description: additional description that the user can display by clicking on the displayed text.
- style: style identifier to be used to represent a point object. The style is defined with the defIconStyle() function.
add3DModel() : add 3D objects
If the kml or kmz file is meant to be displayed in Google Earth, it is possible to add 3D objects in Collada format (with .dae extension). Such objects can be built with the Sketchup software for example.
The add3DModel() function can be used in four different ways. The first two are equivalent, with only the (begin and end) date formats that change. The other two will add the possibility of regrouping object types in separate folders:
add3DModel(Double posX, Double posY, Double orientation, Double size, String date_start, String date_end, String dae_model)
add3DModel(Double posX, Double posY, Double orientation, Double size, Date date_start, Date date_end, String dae_model)
add3DModel(String folder, Double posX, Double posY, Double orientation, Double size, String date_start, String date_end, String dae_model)
add3DModel(String folder, Double posX, Double posY, Double orientation, Double size, Date date_start, Date date_end, String dae_model)
Détail des arguments :
- folder: identifier of folder to which the 3D objects will be added. If the folder does not exist, it will automatically be created.
- posX and posY: coordinates of the location where the 3D object will be placed. These coordinates are of course defined in the coordinate system of the project.
- orientation: orientation (in degres) of the 3D object. The value must be between 0.0 and 360.0
- size: relative size of the object. Set size to 1.0 to display in the original size. For example 0.5 will display it twice smaller and 3.5 make it three and a half times bigger.
- date_start: date when folder content is displayed on the globe. In case date is in text format, this is the kml format date encoding type to be used.
- date_end: date when folder content disappears from the globe. In case date is in text format, this is the kml format date encoding type to be used.
- dae_model: name (and path) of the file containing the 3D model to be added.
defIconStyle() : define icon style associated with point objects and labels
The defIconStyle() function is used to specify a small image (icon) that will be displayed to represent point objects or labels. If no style is set, the default icon will be displayed. In Google Earth it will be the yellow pin: 
The syntax is as follows:
defIconStyle(String style_name, String image_file, Double size, Double orientation)
Détail des arguments à fournir :
- style_name: identifier of the style. The style name will be used when adding content using functions like addGeometry().
- image_file: name (and path) of a jpg or png file (which is preferable because the possibility of having transparent pixels) which will be used to represent point data or labels.
- size: relative size of the image. Set size to 1.0 to display in the original size. For example 0.5 will display it twice smaller and 3.5 make it three and a half times bigger.
- orientation: orientation (in degres) of the image. A value of 0.0 will orient the top of the image towards the North. For example, a value of 90.0 will orient the top of the image towards the East, and 270.0 towards the West.
defStyle() : define display styles for lines and polygons
The defStyle() function is used to specify colour and thickness of line objects and polygon boundaries, and also the colour of the surface inside polygons.
Two syntaxes are available for this function:
defStyle(String style_name, Double line_thickness, Color line_color, Color surface_color)
defStyle(String style_name, Double line_thickness, String line_color, String surface_color)
Argument details:
- style_name: identifier of the style. The style name will be used when adding content using functions like addGeometry().
- line_thickness: line thickness in pixels
- line_color: line colour. According to the syntax chosen, colour can be specified using the Color type of Ocelet, or the text color coding used in the KML format.
- surface_color: polygon fill colour. According to the syntax chosen, colour can be specified using the Color type of Ocelet, or the text color coding used in the KML format.
defStyleRange() : define an indexed series of styles for polygon display
The defStyleRange() function is similar to the defStyle() function but allows the generation of a series of numbered style names, with each style containing a different colour.
The syntax is as follows:
defStyleRange(String name_prefix, Double line_thickness, List<Color> surface_colors, Double line_color_prop)
Argument details:
- name_prefix: name prefix to identify styles. To this prefix will automatically be added an order number. For example, if the prefix is "level", the styles names "level1", "level2", "level3", etc. will be available according to the number of colours in the surface_colors list.
- line_thickness: line thickness in pixels
- surface_colors: list of colours for polygon fill. The number of colours in the list will set the number of styles defined in the KmlExport datafacer, with an index per style.
- line_color_prop: the line colors will be generated by applying a lightening coefficient (or darkening if the coefficient has a negative value) to the fill colors. The value of that coefficient is expected here and should be within the range -1.0 .. 1.0. For example a value of 0.3 will generate line colors that are 30% lighter than the corresponding fill colors. Using -0.3 will generate line colors that are 30% darker than the corresponding fill colors.
remove() : delete the file
Syntax:
remove()
This function will delete the kml (or kmz) file to which the datafacer points.
saveAsKml(), saveAsKmz() : save a file in kml or kmz format
The content of the datafacer can be saved either in kml (uncompressed) or kmz (compressed) formats using two separate functions. Each of these functions come in two different syntaxes:
saveAsKml()
saveAsKml(String file_name)
saveAsKmz()
saveAsKmz(String file_name)
The saveAsKml() and saveAsKmz() functions without argument will use the file name specified in the definition of the datafacer (or the last name set using setFileName()).
If a file name is given as argument, that file name will be used.
setFileName() : change the file name of a KmlExport datafacer
Syntax:
setFileName(String file_name)
Note that this function only modifies the file name that will be used in the next call to the saveAsKml or saveAsKmz functions. Neither the style definitions, nor the content already added to the datafacer are changed.
The functions whose names start with set can be used without the set, as if a variable is being updated. These two expressions are thus equivalent:
kmlexp.setFileName("output/newplotmap.kml")
or
kmlexp.fileName = "output/newplotmap.kml"
RasterFile
This type of datafacer allows reading files in raster format. For the time being, we recommend the use of GeoTiff image file format.
Definition of a RasterFile type datafacer
A RasterFile datafacer can be defined using one of the following functions:
RasterFile(String file_name, String EPSGcode)
RasterFile(String file_name)
RasterFile(String folder_name, String EPSGcode)
RasterFile(String folder_name)
-
The first argument is the path to the file in raster format. It can also be the path to a folder that may contain several rester files. In that case, the files are sorted in alphanumerical order and the first one is read.
- The second argument sets the coordinate system used for the geographical data stored in the file.
Example of the definition of a RasterFile datafacer
In the case of a Digital Terrain Model (DTM), each pixel contains an altitude value. First, an entity has to be defined with a property to hold the altitude value, and another property of type "Cell" that corresponds to the shape of the pixel:
entity DtmCell {
property Cell cell
property Double altitude
}The datafacer definition then refers to that entity (through the match clause):
datafacer Dtm {
data RasterFile("data/dtm25m_sa.tif","EPSG:2975")
match DtmCell {
altitude : "0"
}
}As defined here, this datafacer prepares for the reading of dtm25m_sa a GeoTiff file.
The match clause defines the correspondance between the altitude property of the Dtmcell entity and the band number of the raster file.
Once defined, the datafacer can be used in the scenario.
Using a RasterFile datafacer in a scenario
The first thing to do is to assign a variable with a copy (an instance) of the datafacer defined. In the current example, it can be done like this:
fix dtmRaster = new DtmreadAll(): to read a RasterFile
This fonction can be used in two ways:
readAllName of the entity specified in match()
readAllName of the entity specified in match(clip geometry)
With the first function, the whole raster file is read and the number of entities created correspond to the number of pixels present in the raster file, that is, DtmCell in the previous example. Each entity created will be initialised with the values contained in one band of the raster file, as specified in the match clause of the datafacer definition.
For example, this is to read the data and obtain a list of DtmCell entities:
fix list_cells = dtmRaster.readAllDtmCell // list_cells contains a list of initialised entities
// For checking and to know how many DtmCell entities have been created
// you may for example display the size of the list, which is also the number of pixels in the raster:
println("We have obtained "+list_cells.size+" DtmCell entities.")The second will do the same, but for only part of the rasterfile. It returns a list of DtmCell entities contained in the envelope of the clip geometry passed in as argument. For example, the clip geometry can be a MultiPolygon type property of an entity, or the envelope of a Shapefile.
setDirectory(): change the folder
Syntax:
setDirectory(String folder_path)
It is possible to change the folder containing the raster files by giving a new path:
dtmRaster.setDirectory("data/dtm_folder")
fix list_cells2 = dtmRaster.readAllDtmCellFollowing these two lines, list_cells2 contains a new list of entities initialised with the content of the first among the files sorted in alphanumerical order.
next(): go to next file in directory
Syntax:
next()
If a directory has been passed on as parameter in the definition of the datafacer, the function next() will set the next file to be read as the next file in alphanumerical order in the directory.
dtmRaster.next()
fix list_cells2 = dtmRaster.readAllDtmCellupdate(): update entity properties
Syntax:
update()
If a directory has been passed on as parameter in the definition of the datafacer, the entity properties defined in the match clause can be updated, for example, after using the next() function.
dtmRaster.next()
dtmRaster.updateIn that case, the last dtmCell entities created with the readAllDtmCell function have their properties updated with the next raster file in the directory.
hasNext(): Check if the directory still has another file in the list
If a directory has been passed on as parameter in the definition of the datafacer, the hasNext() function checks whether the directory contains another file in the sorted list with respect to the current file.
Syntax:
hasNext()
while(dtmRaster.hasNext){
dtmRaster.next
dtmRaster.update
}In this example, the datafacer will check if there is a following file, and as long as it is the case, it will set position on it with the next() function. The entities are then updated using the update() function.
setFileName(): change file name
Syntax:
setFileName(String path_to_file)
If there is another raster file to be read, the same datafacer can be used, just by changing the file name.
dtmRaster.setFileName("data/dtm25m_sa2.tif")
fix list_cells2 = dtm.readAllDtmCellFollowing these two lines, list_cells2 contains a new list of entities initialised with the content of the new file passed on as parameter.
If a directory had been passed on as parameter in the definition of the datafacer, the file specified as parameter in the path will be selected. In that case, the next() function allows targeting the next file starting from that one.
getBoundaries(): Obtain the envelope of the raster as a Polygon
Syntax:
getBoundaries()
This function returns a Polygon that represents the envelope of the raster file. This polygon can, for example, be used as clip polygon when reading another raster file that has a larger envelope.
let polygon = dtmRaster.getBoundaries()
fix list_cells2 = dtmRaster2.readAllDtmCell(polygon)After these two lines, list_cells2 contains a new list of entities initialised with the content of the new raster file that had been clipped using the envelope.
setFileFormat() : Specify the extension of the files to be read
Syntax:
setFileFormat(String file_extension)
This function selects the files which extension has been passed on as parameter. The file extension is specified with a String type that starts with a ".", like for example ".tif".
let polygon = dtmRaster.setDirectory("data/dtmDir")
dtmRaster.setFileFormat(".tif")After these two lines, only the files with a ".tif" extension will be read when the next() function is used.
RasterExport
A datafacer to export a list of cell entities into a raster file in Geotiff format.
Definition of a datafacer of type RasterExport
A RasterExport datafacer is instanciated directly within the scenario:
let rasterExport = new RasterExport()Example using a RasterExport type datafacer
Consider the case of an entity having a cell property as spatial representation and an altitude property containing altitude values corresponding to a DTM. The entity can be defined in this way:
entity DtmCell {
property Cell cell
property Double altitude
}export(): save a file in raster format
Syntax:
export(list_cell_entities, output_path, EPSG, entity_property_to_export)
Consider list_dtmcells a list of DtmCell entities containing altitude values. By using a RasterExport datafacer, it is possible to specify the property of the DtmCell entities that need to be saved in Geotiff format:
let rasterExport = new RasterExport
rasterExport.export(list_dtmcells, "output/myDtm.tif","EPSG:2975", "altitude")Following these two lines, a raster file called "myDtm.tif" that has a band containing altitude values of each of the entities in the list_dtmcells is created and placed in the output directory.
GraphMLExport
This datafacer allows building and saving graphs in GraphML format. This format is used in various software (like Gephi or Yed) for displaying and manipulating graphs, and also in librairies like GraphIO.jl in Julia or pygraphml in Python for example.
Defining a datafacer of type GraphMLExport
On a le choix entre définir d'abord un datafacer à l'aide du mot clé datafacer puis créer une instance de cette définition dans le scénario. Ou créer directment une instance de GraphMLExport dans le scnénario.
Pour la première méthode on définit d'abord un datafacer de la manière suivante :
datafacer DGrml {
data GraphMLExport("output/mongraphe.graphml)
}Puis on l'instancie dans le scérario :
fix grml = new DGrmlPour la seconde méthode on instancie directement GraphMLExport dans le scenario :
fix grml = new GraphMLExport()ou en fournissant aussi un fichier d'exportation :
fix grml = new GraphMLExport("output/monGraphe.graphml")L'instance de GraphMLExport ainsi créée correspond à un graphe vide. Si on l'enregistre tel quel (avec grml.save) on obtient un fichier qui contient ceci :
<?xml version="1.0" encoding="UTF-8"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns
http://graphml.graphdrawing.org/xmlns/1.1/graphml.xsd">
</graphml>Pour y ajouter du contenu, on utilise des fonctions permettant d'ajouter un graphe (ou plusieurs), des noeuds, des arêtes, et éventuellement des propriétés attachées à ces différents éléments.
La première chose à faire est donc d'ajouter au moins un graphe :
graph() : add a graph
Cette fonction ajoute un graphe (vide à ce stade) et retourne un identifiant de graphe dont on aura besoin pour y ajouter du contenu. Le format GraphML permet d'avoir plusieurs graphes dans un même fichier, et chaque graphe a un identifiant qui permet de les distinguer.
Il est aussi possible d'emboiter une graphe dans un noeud d'un autre graphe. Il faut pour cela indiquer l'identifiant du noeud dans lequel on souhaite placer un graphe.
Plusieurs formes sont disponibles pour la création de graphe :
String graph(): ajoute un graphe et retourne son identifiant.
String graph(node_id): ajoute un graphe dans le noeud identifié parnode_idet retourne l'ìdentifiant du graphe créé.
Ce deux premières formes produisent des graphes non orientés. On peut créer des graphes orientés avec les fonctions :
String directedGraph(): ajoute un graphe orienté et retourne son identifiant.
String directedGraph(node_id): ajoute un graphe orienté dans le noeud identifié parnode_idet retourne l'ìdentifiant du graphe créé.
Dans l'exemple qui suit on crée une instance de GraphMLExport et on y ajoute un graphe, puis on sauve le resultat dans un fichier :
fix grml = new GraphMLExport("output/monGraphe.graphml")
g_id = grml.graph
grml.saveLe fichier produit contient ceci (on a remplacé les informations de l'en-tête par ... pour faciliter la lecture) :
<?xml version="1.0" encoding="UTF-8"?>
<graphml ... >
<graph edgedefault="undirected" id="g1"/>
</graphml>
node() : add a node
Deux fonctions sont disponibles pour ajouter un noeud à un graphe :
String node(graph_id): ajoute un noeud au graphe désigné par l'identifiantgraph_idfourni en argument. Cette fonction génère un identifiant de noeud et retourne cet identifiant.
String node(graph_id, node_id): ajoute un noeud au graphe désigné par l'identifiantgraph_idfourni en argument. Cette fonction utilise l'identifiant de noeudnode_idfourni en second argument et retourne cet identifiant.
Voici un exemple où l'on crée un premier noeud sans fournir d'identifiant, puis un deuxième où on fournit l'identifiant "node_b" :
fix grml = new GraphMLExport("output/monGraphe.graphml")
fix g_id = grml.graph
fix n_ida = grml.node(g_id)
fix n_idb = grml.node(g_id,"node_b")
grml.saveLe fichier GraphML produit contient ceci :
<?xml version="1.0" encoding="UTF-8"?>
<graphml ... >
<graph edgedefault="undirected" id="g1">
<node id="n2"/>
<node id="node_b"/>
</graph>
</graphml>
edge() : add an edge
Deux fonctions sont diponibles pour ajouter une arête à un graphe :
String egde(graph_id, source_node_id, target_node_id): ajoute une arête au graphe désigné par l'identifiantgraph_idfourni en argument. Cette arête va relier les deux noeuds dont les identifiants sont fournis en arguments. Cette fonction génère un identifiant d'arête et retourne cet identifiant.
String egde(graph_id, source_node_id, target_node_id, edge_id): ajoute une arête au graphe désigné par l'identifiantgraph_idfourni en argument. Cette arête va relier les deux noeuds dont les identifiants sont fournis en arguments. Cette fonction utlise l'identifiant d'arêteedge_idet retourne cet identifiant.
Si le graphe ne contient pas encore de noeud avec les identifiants fournis (source_node_id ou target_node_id) alors ces noeuds seront automatiquement céés et ajoutés au graphe. Il est donc possible d'ajouter un ensemble de noeuds en ajoutant des arêtes ayant ces noeuds comme extrémités, sans avoir besoin d'ajouter ces noeuds au préalable.
Voici un exemple de création de noeuds et d'arêtes :
fix grml = new GraphMLExport("output/monGraphe.graphml")
fix g_id = grml.graph
fix n_ida = grml.node(g_id)
fix n_idb = grml.node(g_id,"node_b")
fix e_idc = grml.edge(g_id,n_ida,n_idb)
fix e_idd = grml.edge(g_id,n_idb,"node_c")
grml.saveLors de la création de la deuxième arête, il est fait référence à un noeud "node_c" qui n'est pas encore présent dans le graphe. On pourra constater que celui-ci a étée ajouté automatiquement.
Le fichier GraphML produit contient ceci :
<?xml version="1.0" encoding="UTF-8"?>
<graphml ... >
<graph edgedefault="undirected" id="g1">
<node id="n2"/>
<node id="node_b"/>
<edge id="e3" source="n2" target="node_b"/>
<node id="node_c"/>
<edge id="e4" source="node_b" target="node_c"/>
</graph>
</graphml>
attribute() : add an attribute and its value
Les attributs sont des couples (nom,valeur) que l'on peut attacher à un graphe, un noeud ou une arête. Tout comme les autres éléments, les attributs possèdent un identifiant uniaue qui peut soit être généré, soit fourni lors de la création.
Attention, lorsque l'on demande à attacher un attribut à un élément, il faut que cet élément ait déjà été ajouté dans le datafacer GraphMLExport sans quoi, ne sachant pas à quoi le rattacher, la fonction ne fait rien.
Deux fonctions sont disponibles pour ajouter un attribut à un élément :
String attribute(eln_id, name, value): ajoute un attribut à l'élément désigné par son identifianteln_id(il peut s'agir d'un graphe, un noeud ou une arête). Cette fonction génère un identifiant pour cet attribut et retourne cet identifiant.
String attribute(eln_id, name, value, at_id): ajoute un attribut à l'élément désigné par son identifianteln_id(il peut s'agir d'un graphe, un noeud ou une arête). Cette fonction utilise l'identifiant d'attributat_idqui est fourni en dernier argument.
Par exemple pour ajouter un attribut de couleur à un noeud dont l'identifiant est node_c cela peut s'écrire de la façon suivante :
fix atid1 = grml.attribute("node_c","color","red")Attribute default value
Quand on attache un attribut avec son nom et sa valeur à un élément comme un noeud ou une arête, les logiciels qui liront le fichier graphlm peuvent s'attendre à ce que tous les noeuds ou toutes les arêtes portent aussi un attribut du même nom avec une valeur.
Pour ne pas être obligé de définir ces valeurs partout on peut fournir une valeur par défaut à l'aide de la fonction :
setAttributeDefault(at_id,defaultValue): permet de fournir une valeur par défaut pour tous les attributs similaires à celui dont l'identifiantat_idest fourni en argument. Par "similaire" on entend les attributs qui portent le même nom et qui sont attachès au même type d'élément (graphe, noeud ou arête).
Dans la suite de l'exemple précédent on pourrait définir une couleur par défaut pour tous les noeuds du graphe avec :
grml.setAttributeDefault(atid1,"white")